filmov
tv
What is a Spark Dataframe?

Показать описание
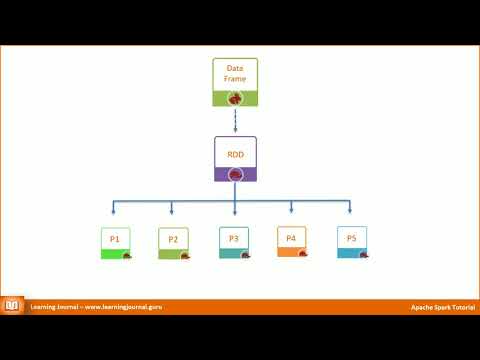
Spark Dataframe is a distributed collection of data, which was released in spark 1.3 release. You may be wondering, even the RDD is a distributed collection of data, then how really is the dataframe different from RDD. Yes, there are lot of similarities with the RDD that dataframe has. Like RDD, Dataframe is also immutable, lazily evaluated, distributed dataset, can be created from different sources, supports different file formats.
1) The difference is that the Dataframe is organized into named columns, whereas a RDD is not.
2) Also, the dataframe comes with a Tungsten component that helps to store the data in binary format, which helps avoid serialization and garbage collection.
3) Dataframe also comes with a catalyst optimizer, which helps spark to reevaluate the physical and logical query execution plan resulting in a new optimized DAG.
To summarize Dataframe is a distributed collection of data that is organized into named columns, which comes with custom memory management (Tungsten component) and optimization features (Catalyst optimizer)
1) The difference is that the Dataframe is organized into named columns, whereas a RDD is not.
2) Also, the dataframe comes with a Tungsten component that helps to store the data in binary format, which helps avoid serialization and garbage collection.
3) Dataframe also comes with a catalyst optimizer, which helps spark to reevaluate the physical and logical query execution plan resulting in a new optimized DAG.
To summarize Dataframe is a distributed collection of data that is organized into named columns, which comes with custom memory management (Tungsten component) and optimization features (Catalyst optimizer)
 0:01:09
0:01:09
 0:13:32
0:13:32
 0:05:19
0:05:19
 0:04:29
0:04:29
 0:05:15
0:05:15
 0:06:32
0:06:32
 0:11:01
0:11:01
 0:10:47
0:10:47
 1:21:14
1:21:14
 0:20:08
0:20:08
 0:16:43
0:16:43
 1:49:02
1:49:02
 0:02:39
0:02:39
 0:12:41
0:12:41
 0:03:45
0:03:45
 0:08:40
0:08:40
 0:11:45
0:11:45
 0:05:12
0:05:12
 0:01:04
0:01:04
 0:17:13
0:17:13
 0:10:32
0:10:32
 0:03:53
0:03:53
 0:08:54
0:08:54
 0:08:37
0:08:37