filmov
tv
video 1.1. intro to stats

Показать описание
Intro, descriptive and inferential statistics, populations and samples.
Closed captioning text:
 1:18:03
1:18:03
1. Introduction to Statistics
 0:13:00
0:13:00
What Is Statistics: Crash Course Statistics #1
 0:14:22
0:14:22
Introductory Statistics Lecture 1 Introduction and Chapter 1 Part 1
 0:22:36
0:22:36
131 Introduction to Statistics: Lecture 1 (Basics of Statistics)
 0:05:52
0:05:52
Scales of Measurement - Nominal, Ordinal, Interval, Ratio (Part 1) - Introductory Statistics
 0:28:45
0:28:45
Introductory Statistics: Chapter 1--The Nature of Statistics (1.1-1.3) | Math with Professor V
 0:00:05
0:00:05
Statistics Formulas -1
 1:18:33
1:18:33
Stat 1490 Chapter 1: Intro to Stats, Sampling, and Data
 0:07:38
0:07:38
Introductory Statistics for Economics | Part 1 | For Eco Hons, B.Com, BBA, BA & GE Students
 0:06:58
0:06:58
Introduction to Business Statistics: Lesson #1
 0:00:15
0:00:15
Final Example 1 - Intro to Statistics
 0:41:10
0:41:10
AP Statistics Unit 4 Summary Review Video Part 1 - Intro to Probability
 0:07:51
0:07:51
Data Collection 1 • Intro to Stats/Populations & Samples • Stats1 Ex1A • 🤖
 1:19:12
1:19:12
Introduction to Statistics|Statistics chapter-1|BBA|BCA|B.com|Dream Maths
 0:14:24
0:14:24
1. Statistics Subject Introduction in English
 0:13:24
0:13:24
Medical statistics made easy -1 (Introduction to statistics - data, variable and observation)
 0:03:12
0:03:12
Changing Width 1 - Intro to Statistics
 0:06:53
0:06:53
A Gentle Introduction to Non-Parametric Statistics (15-1)
 0:00:19
0:00:19
Cancer Example 1 - Intro to Statistics
 0:27:51
0:27:51
Chapter 1 - An Intro to Business Statistics
 0:02:17
0:02:17
Variances 1 - Intro to Statistics
 0:03:14
0:03:14
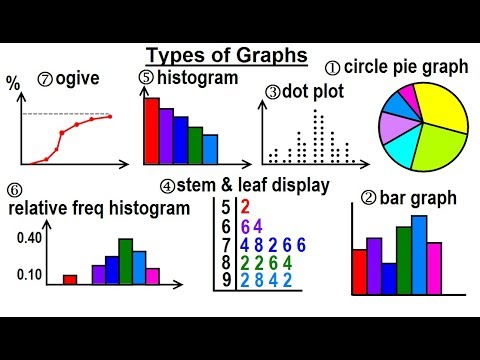
Statistics: Ch 2 Graphical Representation of Data (1 of 62) Types of Graphs
 0:01:47
0:01:47
Verify Loading 1 - Intro to Statistics
 0:01:49
0:01:49
Alternate Formula 1 - Intro to Statistics
Комментарии