filmov
tv
How to use PySpark DataFrame API? | DataFrame Operations on Spark

Показать описание
In this tutorial we will continue with PySpark. In the previous session we covered the setup, learned about the basics of PySpark and explored few of the features that it offers for example DataFrame API and Spark SQL. In this session we will further explore these features before we dive into building data pipelines with PySpark (Spark API).
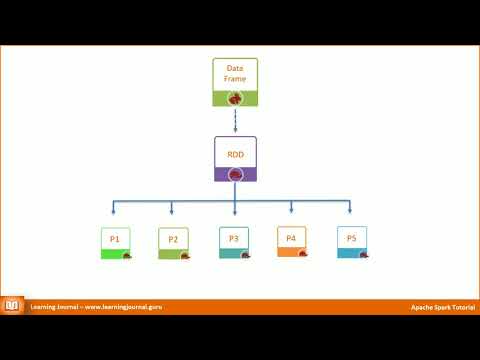
Spark is a distributed engine designed for processing large amount of data. It offers scalability beyond a single machine. If you encounter Pandas memory error due to data size then it is time to explore Spark. It is designed for large data. It is the engine behind the AWS Glue.
Subscribe to our channel:
-------------------------------------------
Follow me on social media!
-------------------------------------------
#apachespark #pyspark #dataframe
Topics covered in this video:
0:00 - Introduction to PySpark
0:28 - Spark in current context of Data
1:16 - Spark DataFrame API
2:22 - Jupyter Notebook
3:00 - Read Data from Database
4:06 - DataFrame API Operations - Rename and Select
4:35 - Sort DataFrame
5:14 - Filter Operation in DataFrame and Spark SQL
7:40 - DataFrame & SQL Join & Aggregate Operation
9:22 - Create new Columns based on condition
11:06 - Replace Null & Drop Columns
Spark is a distributed engine designed for processing large amount of data. It offers scalability beyond a single machine. If you encounter Pandas memory error due to data size then it is time to explore Spark. It is designed for large data. It is the engine behind the AWS Glue.
Subscribe to our channel:
-------------------------------------------
Follow me on social media!
-------------------------------------------
#apachespark #pyspark #dataframe
Topics covered in this video:
0:00 - Introduction to PySpark
0:28 - Spark in current context of Data
1:16 - Spark DataFrame API
2:22 - Jupyter Notebook
3:00 - Read Data from Database
4:06 - DataFrame API Operations - Rename and Select
4:35 - Sort DataFrame
5:14 - Filter Operation in DataFrame and Spark SQL
7:40 - DataFrame & SQL Join & Aggregate Operation
9:22 - Create new Columns based on condition
11:06 - Replace Null & Drop Columns
 0:11:49
0:11:49
PySpark Tutorial 6: PySpark DataFrame Functions | PySpark with Python
 0:16:43
0:16:43
Tutorial 2-Pyspark With Python-Pyspark DataFrames- Part 1
 0:12:14
0:12:14
How to use PySpark DataFrame API? | DataFrame Operations on Spark
 0:06:36
0:06:36
PySpark Tutorial 5: Create PySpark DataFrame | PySpark with Python
 1:49:02
1:49:02
PySpark Tutorial
 0:45:50
0:45:50
Pyspark Dataframe Tutorial | Introduction to Pyspark Dataframes | Pyspark Training | Simplilearn
 0:17:13
0:17:13
PySpark Tutorial: Spark SQL & DataFrame Basics
 0:05:09
0:05:09
How to Integrate PySpark with Jupyter Notebook
 0:07:05
0:07:05
40 Scenario based pyspark interview question | pyspark interview
 0:17:21
0:17:21
The ONLY PySpark Tutorial You Will Ever Need.
 0:12:41
0:12:41
02. Databricks | PySpark: RDD, Dataframe and Dataset
 0:16:28
0:16:28
Tutorial 1-Pyspark With Python-Pyspark Introduction and Installation
 0:10:07
0:10:07
Tutorial 7 - Applying a Function on PySpark DataFrame, Pandas UDFs and Pandas Functions APIs
 0:13:32
0:13:32
Spark Tutorial - Introduction to Dataframes
 0:26:38
0:26:38
2. Create Dataframe manually with hard coded values in PySpark
 0:14:30
0:14:30
Tutorial 3- Pyspark With Python-Pyspark DataFrames- Handling Missing Values
 0:08:52
0:08:52
3. Convert PySpark Dataframe to Pandas Dataframe | #pyspark #azuredatabricks #azuresynapse #spark
 0:07:13
0:07:13
PySpark Tutorial : Show dataframe in PySpark
 0:08:59
0:08:59
Tutorial 4- Pyspark With Python-Pyspark DataFrames- Filter Operations
 0:04:01
0:04:01
Create A Empty or Dummy Pyspark Dataframe in Databricks | dr.dataspark
 0:31:21
0:31:21
Data Wrangling with PySpark for Data Scientists Who Know Pandas - Andrew Ray
 0:02:39
0:02:39
What Is Apache Spark?
 0:17:18
0:17:18
SQL DataFrame functional programming and SQL session with example in PySpark Jupyter notebook
 3:58:31
3:58:31
PySpark Full Course [2024] | Learn PySpark | PySpark Tutorial | Edureka
Комментарии