filmov
tv
Finding scaling laws for Reinforcement Learning

Показать описание
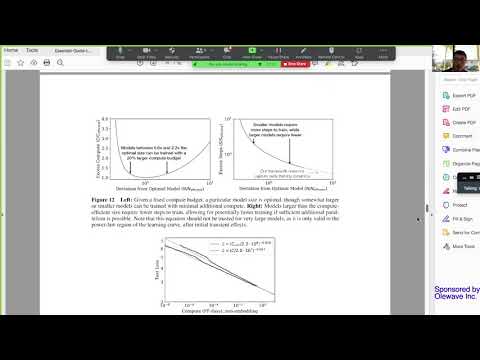
Neural scaling laws have received a lot of attention in recent ML research, ever since it was discovered that generative language models improve their performance as a power law of available resources. Since then, power-law scaling laws seem to pop up in every field and setting imaginable. These laws provide clear instructions on how to train large models on multi-million dollar budgets, and have directly guided the creation of SOTA models like GPT-3. Despite all this, Reinforcement Learning had until recently almost no record of power-law scaling.
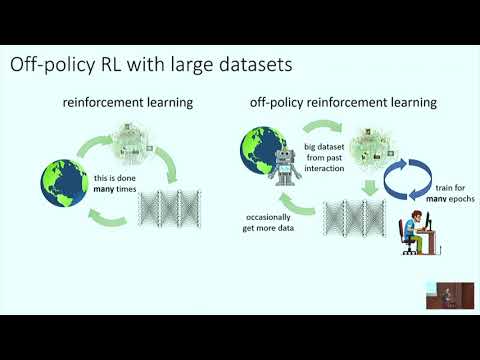
In this talk, Oren Neumann shares how his team found power-law scaling laws for AlphaZero, why any previous attempt to find these laws in RL failed, and how to train a model efficiently when a single training attempt costs several million dollars.
Bio: Oren Neumann is PhD candidate in Complex Systems physics at Goethe University in Frankfurt. Coming from a background in Condensed Matter physics, where emergent power laws have been studied for decades, he focused his research on scaling phenomena in Reinforcement Learning.
In this talk, Oren Neumann shares how his team found power-law scaling laws for AlphaZero, why any previous attempt to find these laws in RL failed, and how to train a model efficiently when a single training attempt costs several million dollars.
Bio: Oren Neumann is PhD candidate in Complex Systems physics at Goethe University in Frankfurt. Coming from a background in Condensed Matter physics, where emergent power laws have been studied for decades, he focused his research on scaling phenomena in Reinforcement Learning.
 0:35:24
0:35:24
 1:14:49
1:14:49
 0:00:29
0:00:29
 1:04:02
1:04:02
 0:00:46
0:00:46
 0:47:38
0:47:38
 0:24:07
0:24:07
 0:35:14
0:35:14
 0:10:53
0:10:53
 1:02:58
1:02:58
 0:16:47
0:16:47
![[short] In deep](https://i.ytimg.com/vi/9k5--UKAi4s/hqdefault.jpg) 0:02:38
0:02:38
 0:38:31
0:38:31
 0:59:36
0:59:36
 0:56:53
0:56:53
 0:17:12
0:17:12
 1:29:14
1:29:14
 0:34:09
0:34:09
 0:46:23
0:46:23
 0:23:08
0:23:08
 0:00:24
0:00:24
 0:22:43
0:22:43
 0:00:16
0:00:16
 0:36:06
0:36:06