filmov
tv
Spark for Data Science, Big and Small, Joseph K. Bradley, 20151024

Показать описание
Joseph K. Bradley, Databricks
Data Science Camp 2015 Keynote
We discuss recent and upcoming advances in Apache Spark to facilitate data science. Spark’s wide adoption largely stems from allowing fast, iterative analysis, both on a laptop and on large computing clusters. This interactivity has led many data scientists to adopt Spark for both exploratory analysis and production modeling and scoring.
In response, the Spark community has been working on key features to further improve the experience of data scientists. This talk will highlight some of these features, mention use cases, and discuss recent and ongoing work on optimizations and extended functionality.
Spark DataFrames, introduced in Spark 1.3, allow manipulation of distributed data using a friendly API inspired by R and Python pandas.
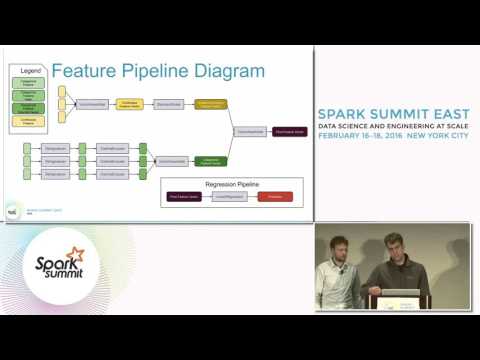
Machine Learning Pipelines, introduced in Spark 1.2, facilitate construction of ML workflows and model tuning.
Spark R, shipped with Spark 1.4, provides an API for R users to work with distributed data, and we continue work towards feature parity for the R API.
For each of these items, we are working on improving integrations with familiar data science tools such as R and Python dataframes and scikit-learn. Initial PMML support, added in Spark 1.4, allows users to export models to other tools and deployments.This talk will be accessible for new Spark users, and will also provide
insights, references, and tips helpful for experienced users.
Speaker Bio
Joseph Bradley is a Spark Committer working on MLlib at Databricks. Previously, he was a postdoc at UC Berkeley after receiving his Ph.D. in Machine Learning from Carnegie Mellon U. in 2013. His research included probabilistic graphical models, parallel sparse regression, and aggregation mechanisms for peer grading in MOOCs.
Data Science Camp 2015 Keynote
We discuss recent and upcoming advances in Apache Spark to facilitate data science. Spark’s wide adoption largely stems from allowing fast, iterative analysis, both on a laptop and on large computing clusters. This interactivity has led many data scientists to adopt Spark for both exploratory analysis and production modeling and scoring.
In response, the Spark community has been working on key features to further improve the experience of data scientists. This talk will highlight some of these features, mention use cases, and discuss recent and ongoing work on optimizations and extended functionality.
Spark DataFrames, introduced in Spark 1.3, allow manipulation of distributed data using a friendly API inspired by R and Python pandas.
Machine Learning Pipelines, introduced in Spark 1.2, facilitate construction of ML workflows and model tuning.
Spark R, shipped with Spark 1.4, provides an API for R users to work with distributed data, and we continue work towards feature parity for the R API.
For each of these items, we are working on improving integrations with familiar data science tools such as R and Python dataframes and scikit-learn. Initial PMML support, added in Spark 1.4, allows users to export models to other tools and deployments.This talk will be accessible for new Spark users, and will also provide
insights, references, and tips helpful for experienced users.
Speaker Bio
Joseph Bradley is a Spark Committer working on MLlib at Databricks. Previously, he was a postdoc at UC Berkeley after receiving his Ph.D. in Machine Learning from Carnegie Mellon U. in 2013. His research included probabilistic graphical models, parallel sparse regression, and aggregation mechanisms for peer grading in MOOCs.
 0:15:40
0:15:40
Spark Tutorial For Beginners | Big Data Spark Tutorial | Apache Spark Tutorial | Simplilearn
 0:02:39
0:02:39
What Is Apache Spark?
 0:43:53
0:43:53
Data Science at Scala with Spark • Dean Wampler • GOTO 2015
 0:10:47
0:10:47
Learn Apache Spark in 10 Minutes | Step by Step Guide
 0:15:42
0:15:42
Apache Spark Announcement | Single node data science meets big data | Keynote Data + AI Summit 2021
 1:49:02
1:49:02
PySpark Tutorial
 0:45:11
0:45:11
Introduction to Big Data & Spark | Big Data & Spark Tutorial - 1 | Edureka
 1:02:47
1:02:47
Spark for Data Science, Big and Small, Joseph K. Bradley, 20151024
 0:03:56
0:03:56
Overview of Hadoop Platform
 0:59:13
0:59:13
Learn Real Time Big Data Analytics Using Python and Spark: Hands-On | Learn Python and Spark
 2:13:30
2:13:30
Training Data Science with Apache Spark
 0:21:31
0:21:31
Fugue: Unifying Spark and Non-Spark Ecosystems for Big Data Analytics
 0:21:13
0:21:13
What to Expect for Big Data and Apache Spark in 2017
 0:30:47
0:30:47
Deep Learning to Big Data Analytics on Apache Spark Using BigDL - Yuhao Yang & Xianyan Jia
 0:04:04
0:04:04
Apache Spark with Scala - Hands On with Big Data!
 0:28:03
0:28:03
MLLeap, or How to Productionize Data Science Workflows Using Spark
 0:29:08
0:29:08
Bringing Big Data Analytics through Apache Spark to .NET
 0:50:30
0:50:30
Big Data Analytics using Spark with Python | PySpark Tutorial | Intellipaat
 0:36:36
0:36:36
Big Data Spark Tutorial | Apache Spark Example | Spark Training | Edureka | Apache Spark Live - 1
 0:14:15
0:14:15
Big Data on Spark | Tutorial for Beginners [Part 25] | Spark - Reading from RDBMS | Great Learning
 0:26:39
0:26:39
Huawei Advanced Data Science With Spark Streaming
 0:08:36
0:08:36
Big Data on Spark | Tutorial for Beginners [Part 2] | Spark History and Overview | Great Learning
 0:44:23
0:44:23
Data Science in 30 Minutes #5: Exploring Wikipedia with Apache Spark
 0:42:20
0:42:20
Introduction to Big Data Hadoop & Spark with Python | PySpark Tutorial | Edureka | PySpark Live ...
Комментарии