filmov
tv
An Uber Journey in Distributed Deep Learning
Показать описание
In this video from the Stanford HPC Conference, Alex Sergeev from Uber presents: An Uber Journey in Distributed Deep Learning.
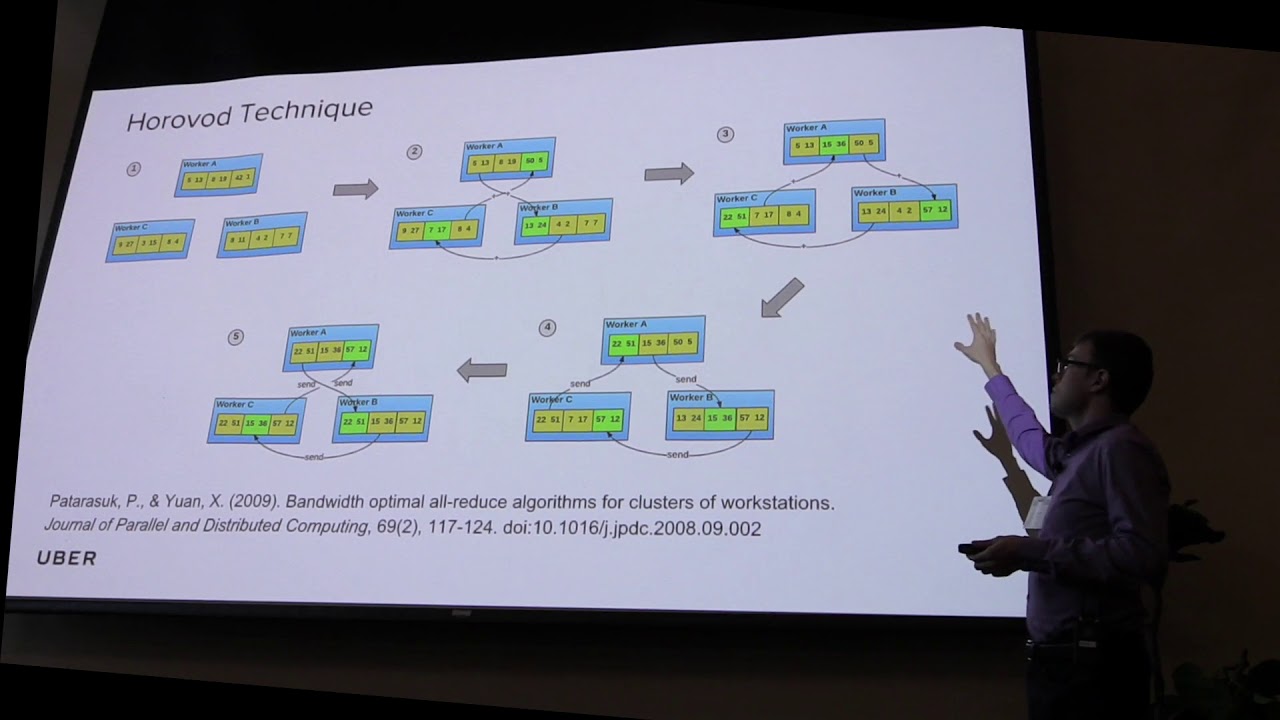
"Uber engineering covers a wide development terrain from autonomous vehicles and trip forecasting to fraud detection and more. Inspired by the works of Baidu, Facebook, et al., Uber has developed “Horovod”, an open source distributed framework for TensorFlow. Inducing a ‘good harvest’, as asserted by ingenious branding influenced by the traditional Russian folk dance of linking hands and dancing in a circle during a planting season, Horovod makes it easy to scale training of deep learning models from a single GPU to hundreds – on one or across multiple servers.
Uber explores the journey in distributed deep learning in two parts. The HPC problem, tools to perform distributed computation; and the ML problem, tweaking model code and hyperparameters.
The talk will touch upon practical aspects, the mechanisms of deep learning training, mechanics of Horovod and performance expectations on standard models such as Inception V3 and ResNet-101; to achieve practical results, using HPC techniques and technologies such as allreduce, RDMA and MPI, training convolutional networks and LSTMs on your favorite supercomputer in hours, versus days/weeks, with the same final accuracy."
and
"Uber engineering covers a wide development terrain from autonomous vehicles and trip forecasting to fraud detection and more. Inspired by the works of Baidu, Facebook, et al., Uber has developed “Horovod”, an open source distributed framework for TensorFlow. Inducing a ‘good harvest’, as asserted by ingenious branding influenced by the traditional Russian folk dance of linking hands and dancing in a circle during a planting season, Horovod makes it easy to scale training of deep learning models from a single GPU to hundreds – on one or across multiple servers.
Uber explores the journey in distributed deep learning in two parts. The HPC problem, tools to perform distributed computation; and the ML problem, tweaking model code and hyperparameters.
The talk will touch upon practical aspects, the mechanisms of deep learning training, mechanics of Horovod and performance expectations on standard models such as Inception V3 and ResNet-101; to achieve practical results, using HPC techniques and technologies such as allreduce, RDMA and MPI, training convolutional networks and LSTMs on your favorite supercomputer in hours, versus days/weeks, with the same final accuracy."
and
 0:19:47
0:19:47
 0:16:18
0:16:18
 0:20:04
0:20:04
 0:13:14
0:13:14
 0:01:54
0:01:54
 0:36:05
0:36:05
 0:05:02
0:05:02
 0:27:00
0:27:00
 0:28:59
0:28:59
 0:47:28
0:47:28
 0:03:18
0:03:18
 0:21:45
0:21:45
 0:00:33
0:00:33
 0:45:56
0:45:56
 0:32:59
0:32:59
 1:22:55
1:22:55
 0:02:15
0:02:15
 0:02:20
0:02:20
 0:30:42
0:30:42
 0:36:32
0:36:32
 0:30:08
0:30:08
![[Uber Seattle] Horovod:](https://i.ytimg.com/vi/fZ9P1v1jtFM/hqdefault.jpg) 0:22:29
0:22:29
 1:06:29
1:06:29
 0:36:56
0:36:56