filmov
tv
99% of data scientists do this mistake #shorts #unfolddatascience #datascience

Показать описание
99% of data scientists do this mistake #shorts #unfolddatascience #datascience
Hello ,
My name is Aman and I am a Data Scientist.
About Unfold Data science: This channel is to help people understand basics of data science through simple examples in easy way. Anybody without having prior knowledge of computer programming or statistics or machine learning and artificial intelligence can get an understanding of data science at high level through this channel. The videos uploaded will not be very technical in nature and hence it can be easily grasped by viewers from different background as well.
If you need Data Science training from scratch . Please fill this form (Please Note: Training is chargeable)
Book recommendation for Data Science:
Category 1 - Must Read For Every Data Scientist:
Ctaegory 2 - Overall Data Science:
Category 3 - Statistics and Mathematics:
Category 4 - Machine Learning:
Category 5 - Programming:
My Studio Setup:
Join Facebook group :
Follow on twitter : @unfoldds
Follow on Instagram : unfolddatascience
Watch python for data science playlist here:
Watch statistics and mathematics playlist here :
Watch End to End Implementation of a simple machine learning model in Python here:
Learn Ensemble Model, Bagging and Boosting here:
Build Career in Data Science Playlist:
Artificial Neural Network and Deep Learning Playlist:
Natural langugae Processing playlist:
Understanding and building recommendation system:
Access all my codes here:
Hello ,
My name is Aman and I am a Data Scientist.
About Unfold Data science: This channel is to help people understand basics of data science through simple examples in easy way. Anybody without having prior knowledge of computer programming or statistics or machine learning and artificial intelligence can get an understanding of data science at high level through this channel. The videos uploaded will not be very technical in nature and hence it can be easily grasped by viewers from different background as well.
If you need Data Science training from scratch . Please fill this form (Please Note: Training is chargeable)
Book recommendation for Data Science:
Category 1 - Must Read For Every Data Scientist:
Ctaegory 2 - Overall Data Science:
Category 3 - Statistics and Mathematics:
Category 4 - Machine Learning:
Category 5 - Programming:
My Studio Setup:
Join Facebook group :
Follow on twitter : @unfoldds
Follow on Instagram : unfolddatascience
Watch python for data science playlist here:
Watch statistics and mathematics playlist here :
Watch End to End Implementation of a simple machine learning model in Python here:
Learn Ensemble Model, Bagging and Boosting here:
Build Career in Data Science Playlist:
Artificial Neural Network and Deep Learning Playlist:
Natural langugae Processing playlist:
Understanding and building recommendation system:
Access all my codes here:
 0:00:40
0:00:40
99% of data scientists do this mistake #shorts #unfolddatascience #datascience
 0:02:44
0:02:44
How to Get Ahead of 99% of Data Scientists
 0:00:25
0:00:25
Why you should not become a data scientist
 0:00:57
0:00:57
How To Get Ahead of 99% of Data Scientists (with ONE Skill)
 0:06:28
0:06:28
Why 99% of Portfolio Projects Are Useless - Data Science
 0:04:55
0:04:55
Biggest mistake 99% of aspiring Data Scientists make! | Ep #23 | Biggest mistake in Data Science
 0:00:16
0:00:16
What is Power BI?
 0:07:29
0:07:29
I applied to 158 data science internships. Here’s what I’d do if I had to do it all over again.
 0:07:15
0:07:15
Confused About Data Science Jobs? Here's What You Need to Know!
 0:28:18
0:28:18
Time Series Secrets That 99% of Data Scientists Get Wrong
 0:08:41
0:08:41
I Tried 50 Data Analyst Courses. Here Are Top 5
 0:10:35
0:10:35
What data scientists need to know but don't learn in school
 0:04:46
0:04:46
7 BEST Data Science Podcasts for 2024
 0:53:20
0:53:20
How to Get Ahead of 99% of Data Scientists with Streamlit (Tips from Tyler Richards)
 0:08:50
0:08:50
How To Make Money as a Data Scientist
 0:00:50
0:00:50
Is PowerBI easy to learn? #codebasics #data #dataanalyst #powerbi
 0:01:00
0:01:00
do you have a DATA scientist on CALL? 📞
 0:00:31
0:00:31
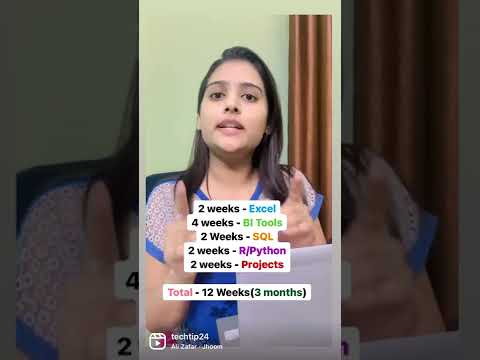
Data Analytics 3 months roadmap #dataanalytics #datascience #upgradeskill #livetraining
 1:09:17
1:09:17
The ONLY Data Science & AI Roadmap You NEED [Step-by-Step Guide]
 0:01:01
0:01:01
Reality of Data Science Jobs 2023🔥 || Data Science Jobs 2023
 0:00:58
0:00:58
Who invented 'Data Scientist'? 🧑🔬 #shorts
 0:11:51
0:11:51
FASTEST Way to Learn Data Science & Get a job in 2024
 0:00:35
0:00:35
Story Of Every Data Analyst #comedy #shorts #short
 0:09:54
0:09:54
Question Of The Decade? Is DSA Required For Data Science? #dsa #datascience
Комментарии