filmov
tv
17: Principal Components Analysis_ - Intro to Neural Computation
Показать описание
MIT 9.40 Introduction to Neural Computation, Spring 2018
Instructor: Michale Fee
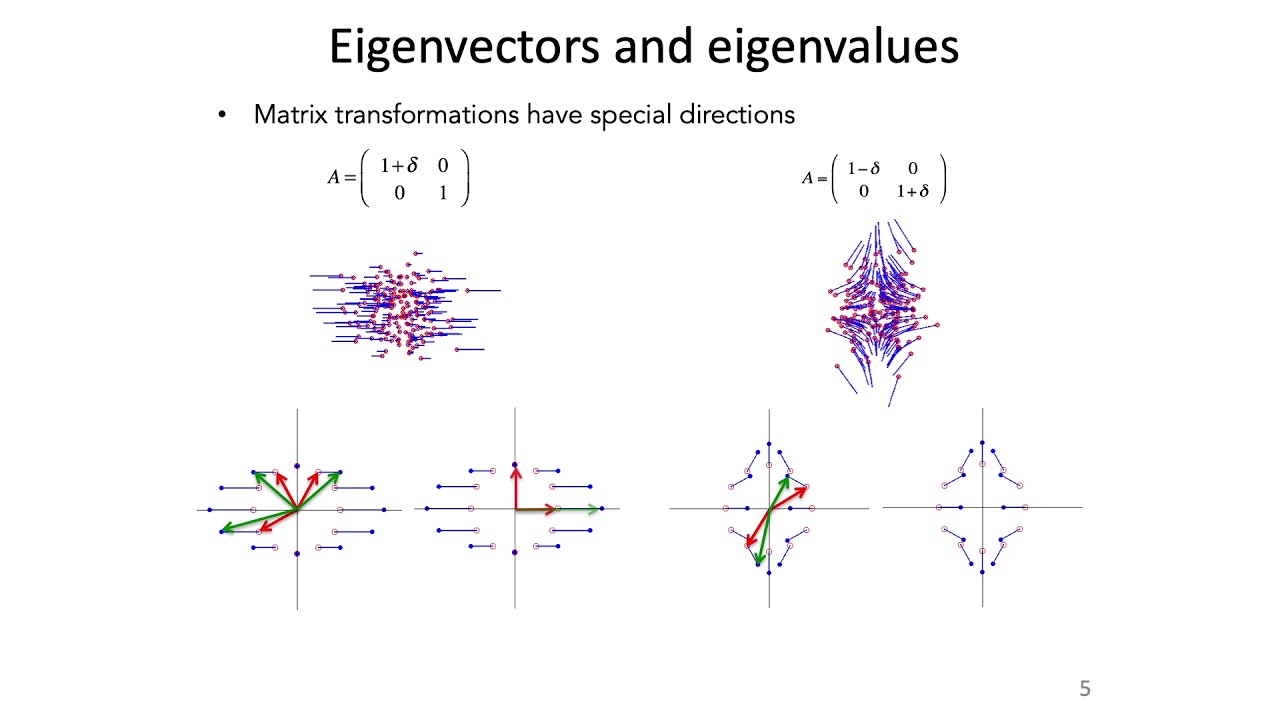
Covers eigenvalues and eigenvectors, Gaussian distributions, computing covariance matrices, and principal components analysis (PCA).
License: Creative Commons BY-NC-SA
We encourage constructive comments and discussion on OCW’s YouTube and other social media channels. Personal attacks, hate speech, trolling, and inappropriate comments are not allowed and may be removed.
Instructor: Michale Fee
Covers eigenvalues and eigenvectors, Gaussian distributions, computing covariance matrices, and principal components analysis (PCA).
License: Creative Commons BY-NC-SA
We encourage constructive comments and discussion on OCW’s YouTube and other social media channels. Personal attacks, hate speech, trolling, and inappropriate comments are not allowed and may be removed.
 1:21:19
1:21:19
17: Principal Components Analysis_ - Intro to Neural Computation
 0:21:58
0:21:58
StatQuest: Principal Component Analysis (PCA), Step-by-Step
 0:06:28
0:06:28
Principal Component Analysis (PCA)
 0:10:56
0:10:56
Principal Component Analysis (PCA) - easy and practical explanation
 0:26:41
0:26:41
M-17. Sample Principal Components
 0:16:25
0:16:25
Principal Components Analysis
 0:30:00
0:30:00
Principal Component Analysis | Learn the Basics of Data Analysis and Machine Learning
 1:00:45
1:00:45
Principal Component Analysis
 0:01:36
0:01:36
Super easy principal components analysis (PCA)
 0:19:53
0:19:53
Principal Components Analysis
 0:54:15
0:54:15
Hands-On Machine Learning with R: Principal Components Analysis (homl01 17)
 0:14:06
0:14:06
PCA, Principal Component Analysis
 0:01:39
0:01:39
Principal Components
 0:02:42
0:02:42
Principal Component Analysis
 0:07:45
0:07:45
Principal Component Analysis Explained
 0:04:33
0:04:33
Question 20 - What are the Steps in Principal Components Analysis
 0:40:25
0:40:25
Sample Principal Components
 0:20:22
0:20:22
PCA : the math - step-by-step with a simple example
 0:16:33
0:16:33
Field Ecology - Principal Components Analysis
 0:03:55
0:03:55
How to create index using Principal component analysis (PCA) in Stata
 0:14:48
0:14:48
Principal component regression (PCR) - explained
 0:24:09
0:24:09
Machine Learning Tutorial Python - 19: Principal Component Analysis (PCA) with Python Code
 0:20:09
0:20:09
Data Analysis 6: Principal Component Analysis (PCA) - Computerphile
 0:12:58
0:12:58
PCA | Principal Components Analysis explained by a Giraffe
Комментарии