filmov
tv
Power of Embeddings with Vector Search | Using Unstructured Data | Future of Data & AI

Показать описание
The total amount of digital data generated worldwide is increasing at a rapid rate. Simultaneously, approximately 80% (and growing) of this newly generated data is unstructured data – data that does not conform to a table- or object-based model.
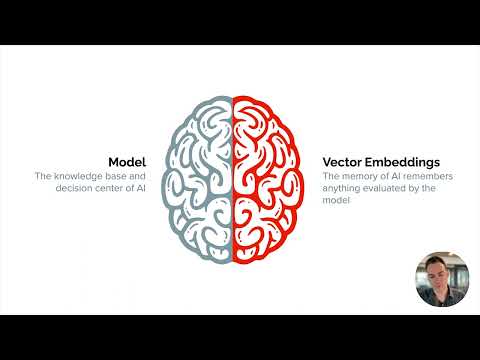
Examples of unstructured data include text, images, protein structures, geospatial information, and IoT data streams. Despite this, the vast majority of companies and organizations do not have a way of storing and analyzing these increasingly large quantities of unstructured data. Embeddings – high-dimensional, dense vectors which represent the semantic content of unstructured data – can remedy this.
In this tutorial, we’ll introduce embeddings and vector search from both an ML- and application-level perspective. This talk will include:
- A high-level overview of embeddings and discuss best practices around embedding generation and usage.
- Build two systems; semantic text search and reverse image search.
- See how we can put our application into production using Milvus - the world’s most popular open-source vector database.
--
Table of Contents:
02:02 – Unstructured data and embeddings
06:45 – Vector search overview
13:40 – Demo time
38:18 – Real-world use cases
About the Speaker: Frank Liu
Frank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai, and worked as an ML engineer at Yahoo in San Francisco.
#vectorsearch #embeddings #vectordatabase #futureofdataandai
Examples of unstructured data include text, images, protein structures, geospatial information, and IoT data streams. Despite this, the vast majority of companies and organizations do not have a way of storing and analyzing these increasingly large quantities of unstructured data. Embeddings – high-dimensional, dense vectors which represent the semantic content of unstructured data – can remedy this.
In this tutorial, we’ll introduce embeddings and vector search from both an ML- and application-level perspective. This talk will include:
- A high-level overview of embeddings and discuss best practices around embedding generation and usage.
- Build two systems; semantic text search and reverse image search.
- See how we can put our application into production using Milvus - the world’s most popular open-source vector database.
--
Table of Contents:
02:02 – Unstructured data and embeddings
06:45 – Vector search overview
13:40 – Demo time
38:18 – Real-world use cases
About the Speaker: Frank Liu
Frank Liu is the Director of Operations & ML Architect at Zilliz, where he serves as a maintainer for the Towhee open-source project. Prior to Zilliz, Frank co-founded Orion Innovations, an ML-powered indoor positioning startup based in Shanghai, and worked as an ML engineer at Yahoo in San Francisco.
#vectorsearch #embeddings #vectordatabase #futureofdataandai
 0:40:10
0:40:10
 0:03:22
0:03:22
 0:08:29
0:08:29
 0:00:57
0:00:57
 0:01:00
0:01:00
 0:00:55
0:00:55
 0:18:41
0:18:41
 0:04:23
0:04:23
 2:56:56
2:56:56
 0:36:23
0:36:23
 0:03:08
0:03:08
 0:04:45
0:04:45
 0:41:00
0:41:00
 0:58:41
0:58:41
 1:11:47
1:11:47
 0:05:59
0:05:59
 0:34:43
0:34:43
 0:06:52
0:06:52
 0:14:35
0:14:35
 0:00:34
0:00:34
 0:20:36
0:20:36
 0:01:26
0:01:26
 0:16:56
0:16:56
 0:20:11
0:20:11