filmov
tv
How to Build a Metadata Driven Data Pipelines with Delta Live Tables

Показать описание
In this session, you will learn how you can use metaprogramming to automate the creation and management of Delta Live Tables pipelines at scale. The goal is to make it easy to use DLT for large-scale migrations, and other use cases that require ingesting and managing hundreds or thousands of tables, using generic code components and configuration-driven pipelines that can be dynamically reused across different projects or datasets.
Talk by: Mojgan Mazouchi and Ravi Gawai
Talk by: Mojgan Mazouchi and Ravi Gawai
 0:08:12
0:08:12
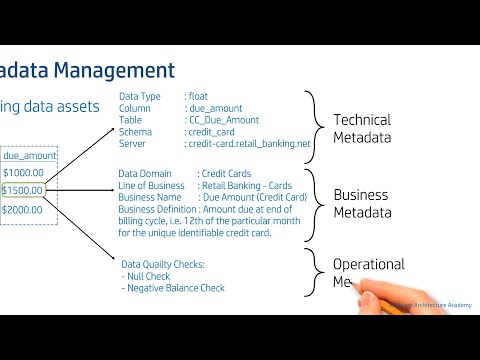
Metadata Management & Data Catalog (Data Architecture | Data Governance)
 0:38:54
0:38:54
How to Build a Metadata Driven Data Pipelines with Delta Live Tables
 1:12:27
1:12:27
How to Build a Metadata Driven Architecture with Microsoft Fabric and Turner Kunkel
 0:27:58
0:27:58
Building a metadata ecosystem with dbt
 0:13:09
0:13:09
What are Metadata Driven Architectures ?
 0:03:55
0:03:55
OpenMetadata Overview #datacatalog #metadata #openmetadata #datadiscovery #lineage #datagovernance
 0:30:35
0:30:35
Data Management - Metadata Management
 0:30:13
0:30:13
Neelesh Salian – Building a metadata ecosystem using the Hive Metastore
 0:26:59
0:26:59
Polkadot Decoded 2024 - BUILD A MODERN DAPP WITH POLKADOT-API
 0:07:02
0:07:02
How to create Managed Metadata at a Site Level
 0:35:12
0:35:12
The Modern Metadata Platform: What, Why, and How?
 0:18:56
0:18:56
Building your first Metadata Driven Azure Data Factory
 0:45:54
0:45:54
Journey of metadata at LinkedIn - Shirshanka Das | Crunch 2019
 0:09:30
0:09:30
Building the metadata highway - Mandy Chessell (IBM)
 0:09:52
0:09:52
How to Build Metadata Repository - How to Build Business Model and Mapping Layer of Repository
 0:14:35
0:14:35
Fabric Data Factory Metadata Driven Pipelines
 0:09:47
0:09:47
How to Build Metadata Repository - How to Test and Validate a Repository - Part-1
 0:04:06
0:04:06
Importing Metadata in Cloud EPM
 0:09:58
0:09:58
How to Build Metadata Repository - How to Build Physical Layer of a Repository
 1:00:41
1:00:41
Metadata Management Fundamentals
 0:00:58
0:00:58
Build vs buy? CEO & co-founder of metadata.io gives his take #businessadvice
 0:57:42
0:57:42
How to set up integrations for metadata ingestion, usage & lineage, and data quality in OpenMeta...
 0:18:50
0:18:50
Mastering Data Validation🔍 : Building a Metadata-Driven Framework for Error-Free Data🎯
 0:38:46
0:38:46
Building an Open Metadata and Governance Ecosystem - Nigel Jones & David Radley, IBM
Комментарии