filmov
tv
Fine Tuning and Enhancing Performance of Apache Spark Jobs

Показать описание
Apache Spark defaults provide decent performance for large data sets but leave room for significant performance gains if able to tune parameters based on resources and job. We’ll dive into some best practices extracted from solving real world problems, and steps taken as we added additional resources. garbage collector selection, serialization, tweaking number of workers/executors, partitioning data, looking at skew, partition sizes, scheduling pool, fairscheduler, Java heap parameters. Reading sparkui execution dag to identify bottlenecks and solutions, optimizing joins, partition. By spark sql for rollups best practices to avoid if possible.
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
About:
Databricks provides a unified data analytics platform, powered by Apache Spark™, that accelerates innovation by unifying data science, engineering and business.
Connect with us:
 0:25:19
0:25:19
Fine Tuning and Enhancing Performance of Apache Spark Jobs
 0:00:50
0:00:50
CapTech 2022 Tech Trends: Fine-Tuning for Enhanced Performance
 0:01:05
0:01:05
Supercharge GPT: Fine-Tuning Techniques for Enhanced NLP Performance
 0:01:03
0:01:03
Use Fine-Tuning to Improve Performance | Model Fine-Tuning - Trailhead Salesforce
 0:13:17
0:13:17
Effective Instruction Tuning: Data & Methods
 0:08:33
0:08:33
What is Prompt Tuning?
 0:00:53
0:00:53
When Do You Use Fine-Tuning Vs. Retrieval Augmented Generation (RAG)? (Guest: Harpreet Sahota)
 0:10:16
0:10:16
[Radboud, U of Amsterdam] Fine Tuning vs. RAG, Which is Better?
 0:13:04
0:13:04
Fine Tune Llama 3.1 (8b) - 2X Faster | With Google Colab and 0$
 0:00:57
0:00:57
Fine-tuning vs Prompt-tuning
 0:53:48
0:53:48
Fine-Tuning LLMs: Best Practices and When to Go Small // Mark Kim-Huang // MLOps Meetup #124
 0:05:57
0:05:57
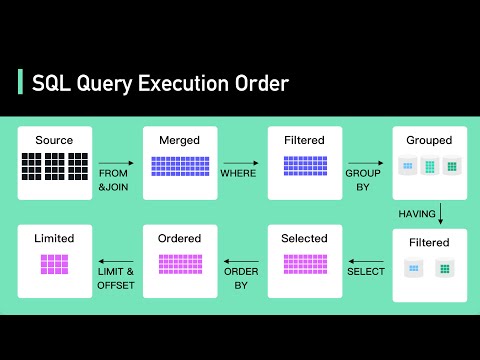
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 0:15:46
0:15:46
Tutorial 2- Fine Tuning Pretrained Model On Custom Dataset Using 🤗 Transformer
 0:21:42
0:21:42
In-Context Learning: EXTREME vs Fine-Tuning, RAG
 0:35:11
0:35:11
Boost Fine-Tuning Performance of LLM: Optimal Architecture w/ PEFT LoRA Adapter-Tuning on Your GPU
 0:00:59
0:00:59
Fine Tuning and Instruction Tuning
 0:03:18
0:03:18
SQL Query Optimization - Tips for More Efficient Queries
 0:00:41
0:00:41
Free Fine-Tuning For GPT-4o Mini Model Explained
 0:29:22
0:29:22
Enhancing Generative AI with InstructLab for Accessible Model Fine-Tuning
 0:00:24
0:00:24
Fine-tuning: Unlocking the Power of Model Adaptation
 0:07:26
0:07:26
Nvidia Geforce Experience Automatic Tuning Review
 0:49:26
0:49:26
Fine tuning Whisper for Speech Transcription
 0:07:34
0:07:34
Improving accuracy using Hyper parameter tuning
 0:46:51
0:46:51
Fine tuning LLMs for Memorization
Комментарии