filmov
tv
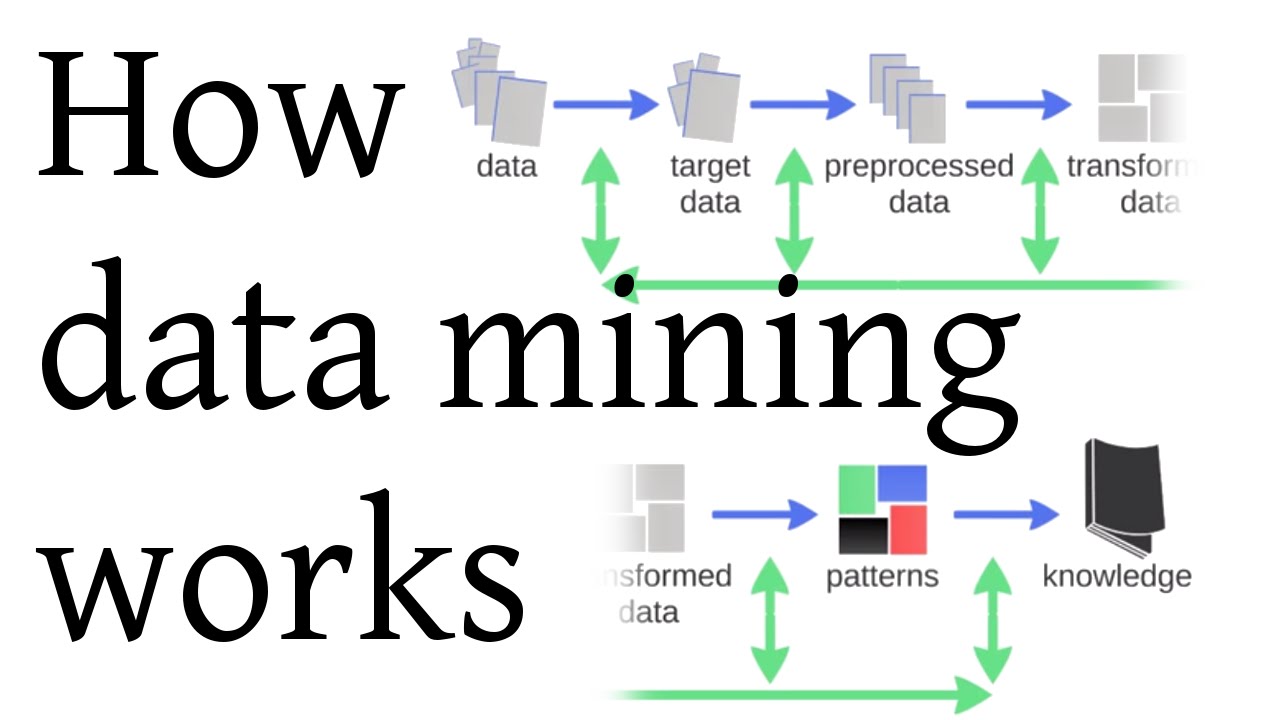
How data mining works
Показать описание
In this video we describe data mining, in the context of knowledge discovery in databases. Nowadays (around 2020) people are using the term 'data science' however with a lot of similarity to what we see in this video, using a reference from 1997.
More videos on classification algorithms can be found at
Subscribe to my channel!
 0:06:53
0:06:53
What is Data Mining?
 0:02:40
0:02:40
What is Data Mining and Why is it Important?
 0:06:05
0:06:05
What is Data Mining
 0:00:53
0:00:53
Data Mining in 1 minute
 0:06:01
0:06:01
How data mining works
 0:13:04
0:13:04
All Major Data Mining Techniques Explained With Examples
 0:06:03
0:06:03
How data mining works || process steps of data mining || Akant 360
 0:01:01
0:01:01
WHAT IS DATA MINING???
 0:29:04
0:29:04
Going from code to product in GitHub - #Kata 50
 0:07:48
0:07:48
Data Mining Fundamentals
 0:16:35
0:16:35
What Is Data Mining | Introduction To Data Mining | Intellipaat
 0:11:13
0:11:13
Data Mining: How You're Revealing More Than You Think
 0:03:32
0:03:32
What Is a Data Warehouse?
 0:09:45
0:09:45
What is Data Mining?
 0:08:40
0:08:40
Data Warehouse and Data Mining, Information management
 0:03:35
0:03:35
Microsoft Data Mining Demo -- Fill from Example
 0:06:25
0:06:25
What is Data Mining|Data Mining in Hindi|Data Mining Tutorial for Beginners|Data Mining
 1:26:59
1:26:59
Data Mining Explained | What is Data Mining?
 0:02:06
0:02:06
What is Bitcoin Mining for Beginners - Short and Simple
 0:02:39
0:02:39
How bitcoin mining works
 0:08:45
0:08:45
Nuggets of Data Gold - Computerphile
 0:05:19
0:05:19
Introduction of Data mining and functionalities in Hindi
 0:05:42
0:05:42
Introduction to Data Warehouse🏺 with Examples
 0:15:05
0:15:05
Data Mining With Excel - Top 4 Skills for ANY Professional
Комментарии