filmov
tv
TensorRT Overview

Показать описание
🔗 Useful Links
w/ love ❤️
📚 About
During inference, TensorRT-based apps are up to 40 times faster than CPU-only systems. You may use TensorRT to improve neural network models trained in all major frameworks, calibrate for reduced precision while maintaining high accuracy, and deploy to hyperscale data centers, embedded systems, or automotive product platforms.
TensorRT is based on CUDA®, NVIDIA's parallel programming model, and allows you to optimize inference using CUDA-XTM libraries, development tools, and technologies for AI, autonomous machines, high-performance computing, and graphics. TensorRT takes advantage of sparse tensor cores on upcoming NVIDIA Ampere Architecture GPUs, delivering an additional performance increase.
For production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation, fraud detection, text generation, and natural language processing, TensorRT provides INT8 using Quantization Aware Training and Post Training Quantization, as well as FP16 optimizations. Reduced precision inference cuts application latency in half, which is essential for many real-time services, as well as autonomous and embedded applications.
🗒️ Chapters:
00:00 Intro to TensorRT
02:20 Prerequisites
03:20 TensorRT Docker Images
06:27 Jupyter Lab within Docker Containers
07:25 Compile TRT OSS
08:26 HuggingFace GPT-2
13:42 PyTorch on CPU/GPU vs TensorRT on GPU
16:42 Outro
🙏 Credits:
#nvidia #tensorRT #pytorch
w/ love ❤️
📚 About
During inference, TensorRT-based apps are up to 40 times faster than CPU-only systems. You may use TensorRT to improve neural network models trained in all major frameworks, calibrate for reduced precision while maintaining high accuracy, and deploy to hyperscale data centers, embedded systems, or automotive product platforms.
TensorRT is based on CUDA®, NVIDIA's parallel programming model, and allows you to optimize inference using CUDA-XTM libraries, development tools, and technologies for AI, autonomous machines, high-performance computing, and graphics. TensorRT takes advantage of sparse tensor cores on upcoming NVIDIA Ampere Architecture GPUs, delivering an additional performance increase.
For production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation, fraud detection, text generation, and natural language processing, TensorRT provides INT8 using Quantization Aware Training and Post Training Quantization, as well as FP16 optimizations. Reduced precision inference cuts application latency in half, which is essential for many real-time services, as well as autonomous and embedded applications.
🗒️ Chapters:
00:00 Intro to TensorRT
02:20 Prerequisites
03:20 TensorRT Docker Images
06:27 Jupyter Lab within Docker Containers
07:25 Compile TRT OSS
08:26 HuggingFace GPT-2
13:42 PyTorch on CPU/GPU vs TensorRT on GPU
16:42 Outro
🙏 Credits:
#nvidia #tensorRT #pytorch
 0:14:54
0:14:54
TensorRT Overview
 0:01:27
0:01:27
Getting Started with NVIDIA TensorRT
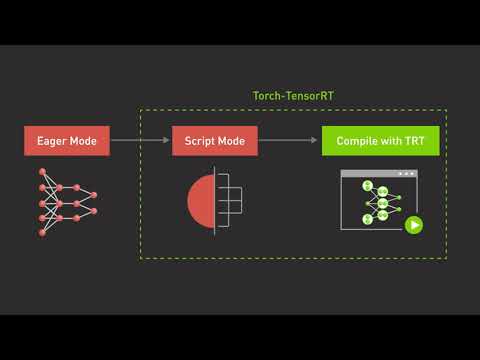 0:01:56
0:01:56
Getting Started with NVIDIA Torch-TensorRT
 0:01:08
0:01:08
What is TensorRT?
 0:01:36
0:01:36
Getting Started with TensorFlow-TensorRT
 0:08:07
0:08:07
NVidia TensorRT: high-performance deep learning inference accelerator (TensorFlow Meets)
 0:01:22
0:01:22
Introduction to NVIDIA TensorRT for High Performance Deep Learning Inference
 0:15:08
0:15:08
NVAITC Webinar: Deploying Models with TensorRT
 0:06:51
0:06:51
NVIDIA Developer How To Series: Introduction to Recurrent Neural Networks in TensorRT
 0:03:13
0:03:13
Nvidia CUDA in 100 Seconds
 0:03:22
0:03:22
TensorRT LLM Introduction
 0:36:25
0:36:25
FASTER Inference with Torch TensorRT Deep Learning for Beginners - CPU vs CUDA
 0:01:49
0:01:49
Faster AI Deployment with NVIDIA TensorRT
 0:01:52
0:01:52
Inference with NVIDIA GPUs and TensorRT
 0:01:08
0:01:08
NVIDIA TensorRT: High Performance Deep Learning Inference
 0:00:51
0:00:51
NVIDIA TensorRT at GTC 2018
 0:06:18
0:06:18
How To Increase Inference Performance with TensorFlow-TensorRT
 0:05:33
0:05:33
NVIDIA Developer How To Series: Accelerating Recommendation Systems with TensorRT
 0:54:03
0:54:03
AI at the Edge TensorFlow to TensorRT on Jetson
 0:36:28
0:36:28
Inference Optimization with NVIDIA TensorRT
 0:08:53
0:08:53
NVIDIA TensorRT 8 Released Today: High Performance Deep Neural Network Inference
 0:18:40
0:18:40
20 Installing and using Tenssorrt For Nvidia users
 0:01:35
0:01:35
Pedestrian Detection on a NVIDIA GPU with TensorRT
 0:03:40
0:03:40
Tensor Cores in a Nutshell
Комментарии