filmov
tv
How to make OCR PDFs on Windows using Tesseract
Показать описание
It's free, it's easy, it's Tesseract, which is an Optical Character Recognition (OCR) engine that detects text in images and overlays the text onto PDFs. Here's how to do it in as short as a tutorial as possible. Medium amount of technical knowledge is helpful.
0:00 Introduction
0:48 Tesseract
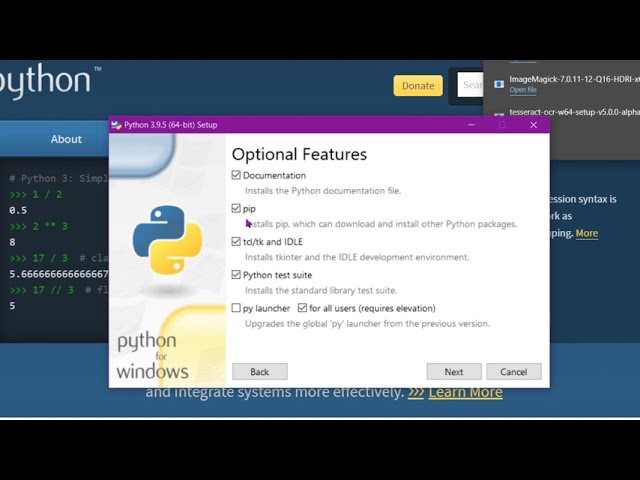
1:32 PATH variable
2:38 ImageMagick
3:21 Python
3:49 GhostScript
5:08 How to run the script
Here are the links for the video:
Here's what each piece of software is doing:
Tesseract: It's what is actually doing the OCR, and putting the text onto images in PDFs. The problem is that Tesseract only takes images as input, so...
ImageMagick: It converts PDFs into a series of PNG images. The problem is it actually needs...
GhostScript: Which provides the tools and libraries that ImageMagick uses. Then there's...
Python: Basic scripting language that is used to run the script I wrote. And that's...
0:00 Introduction
0:48 Tesseract
1:32 PATH variable
2:38 ImageMagick
3:21 Python
3:49 GhostScript
5:08 How to run the script
Here are the links for the video:
Here's what each piece of software is doing:
Tesseract: It's what is actually doing the OCR, and putting the text onto images in PDFs. The problem is that Tesseract only takes images as input, so...
ImageMagick: It converts PDFs into a series of PNG images. The problem is it actually needs...
GhostScript: Which provides the tools and libraries that ImageMagick uses. Then there's...
Python: Basic scripting language that is used to run the script I wrote. And that's...
 0:03:39
0:03:39
How to use OCR and Scan feature | Adobe Acrobat Pro DC
 0:01:43
0:01:43
How To Make Searchable Pdf Files | OCR PDF
 0:09:26
0:09:26
How to use OCR to convert scanned files into editable and searchable documents on Windows
 0:02:36
0:02:36
How to scan to PDF and OCR documents | Create editable and searchable PDFs from paper docs
 0:05:35
0:05:35
Perform an OCR on a PDF document using Adobe Acrobat Pro DC | Pixascene
 0:01:01
0:01:01
How to OCR PDF for Free Online | HiPDF
 0:01:14
0:01:14
How to Perform OCR on a PDF
 0:05:09
0:05:09
PDF Files - converting to OCR
 0:02:56
0:02:56
How To Read PDFS in OCR C# | IronOCR
 0:05:55
0:05:55
How to make OCR PDFs on Windows using Tesseract
 0:01:34
0:01:34
90-Second Tutorial: Make Your PDF Accessible with OCR and Tags (Adobe Acrobat Pro)
 0:01:01
0:01:01
How to OCR PDF on HiPDF Online
 0:02:22
0:02:22
How to make a PDF searchable and batch OCR images
 0:02:04
0:02:04
How to create a PDF from an Image and OCR Scan it | Adobe Acrobat PRO
 0:04:30
0:04:30
How to Convert Scanned Image to Editable Text without using any software
 0:01:11
0:01:11
How to convert PDF files to OCR format
 0:01:29
0:01:29
Quickly learn how to OCR / Make your pdf files text readable
 0:15:40
0:15:40
The BEST PDF TOOLS for Linux: merge, edit, create, annotate, OCR...
 0:00:18
0:00:18
Read PDF Files with GitHub Copilot #pdfreader #ocr #textscanner #copilot
 0:00:21
0:00:21
How to convert image to Searchable PDF with Aspose.OCR
 0:00:14
0:00:14
OCR - Image to Text Converter
 0:00:12
0:00:12
Scan Texts & Images | Convert to PDF with OCR | PDF Scanner, Generator & Editor App for iPho...
 0:00:50
0:00:50
OrbitNote - How to OCR Scan your PDFs
 0:08:23
0:08:23
Perform Optical Character Recognition (OCR) on Documents with PDF-XChange Editor
Комментарии