filmov
tv
ORPO: Monolithic Preference Optimization without Reference Model (Paper Explained)
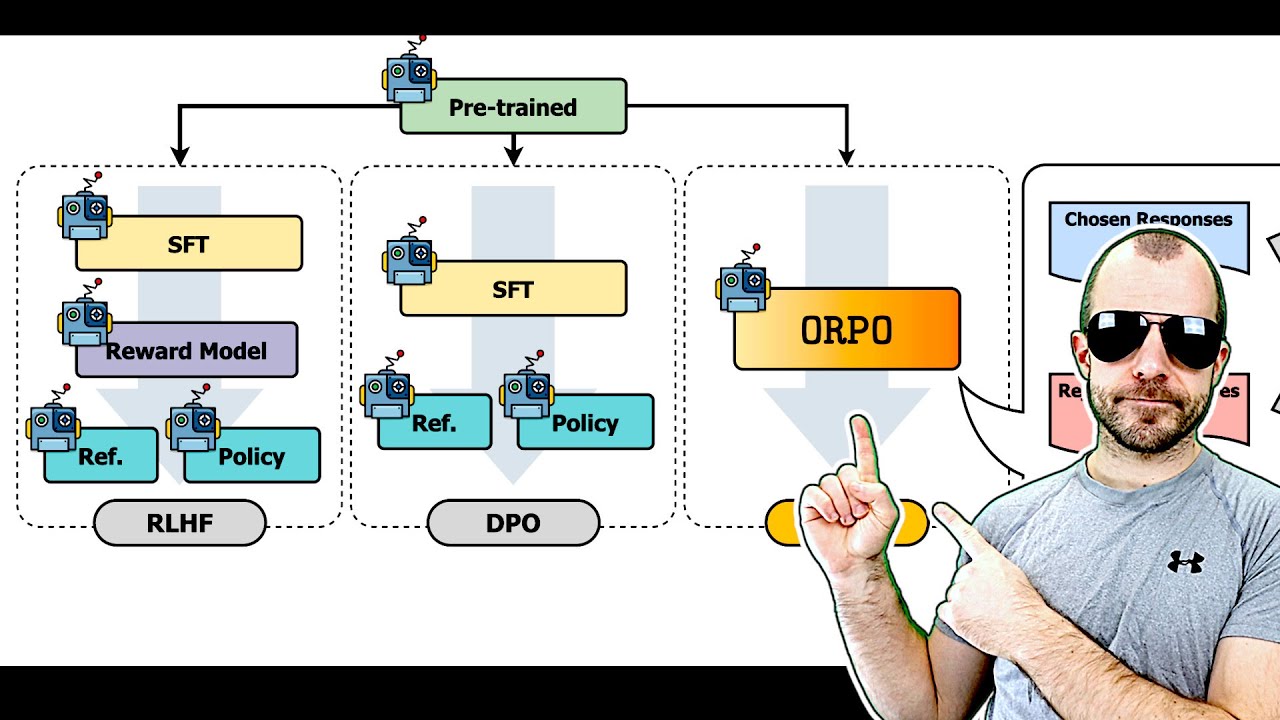
Показать описание
Abstract:
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context of preference alignment, emphasizing that a minor penalty for the disfavored generation style is sufficient for preference-aligned SFT. Building on this foundation, we introduce a straightforward and innovative reference model-free monolithic odds ratio preference optimization algorithm, ORPO, eliminating the necessity for an additional preference alignment phase. We demonstrate, both empirically and theoretically, that the odds ratio is a sensible choice for contrasting favored and disfavored styles during SFT across the diverse sizes from 125M to 7B. Specifically, fine-tuning Phi-2 (2.7B), Llama-2 (7B), and Mistral (7B) with ORPO on the UltraFeedback alone surpasses the performance of state-of-the-art language models with more than 7B and 13B parameters: achieving up to 12.20% on AlpacaEval2.0 (Figure 1), 66.19% on IFEval (instruction-level loose, Table 6), and 7.32 in MT-Bench (Figure 12). We release code and model checkpoints for Mistral-ORPO-α (7B) and Mistral-ORPO-β (7B).
Authors: Jiwoo Hong, Noah Lee, James Thorne
Links:
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
 0:33:26
0:33:26
ORPO: Monolithic Preference Optimization without Reference Model (Paper Explained)
 0:24:05
0:24:05
ORPO: NEW DPO Alignment and SFT Method for LLM
 0:18:18
0:18:18
PR-482: ORPO: Monolithic Preference Optimization without Reference Model
![[Paper Review] ORPO:](https://i.ytimg.com/vi/L6wlJnpX0Ng/hqdefault.jpg) 0:27:40
0:27:40
[Paper Review] ORPO: Monolithic Preference Optimization without Reference Model
 0:09:10
0:09:10
Direct Preference Optimization: Forget RLHF (PPO)
 0:30:55
0:30:55
Combined Preference and Supervised Fine Tuning with ORPO
 0:05:50
0:05:50
ORPO: The Latest LLM Fine-tuning Method | A Quick Tutorial using Hugging Face
 1:06:43
1:06:43
From RLHF with PPO/DPO to ORPO + How to build ORPO on Trainium/Neuron SDK
 0:05:18
0:05:18
Paper - 'FINE-TUNING LARGE LANGUAGE MODELS FOR DOMAIN ADAPTATION' - Audio Podcast
 0:08:57
0:08:57
AutoTrain: Train ANY Large Language Model with 1 Command
 0:42:09
0:42:09
Data Exchange Podcast (Episode 236): Jiwoo Hong and Noah Lee of KAIST AI
 0:13:36
0:13:36
Fine-Tune Llama 3 Using ORPO on Your Own Dataset
 0:10:46
0:10:46
Trying out Mixtral 8x22B MoE fine tuned Zephyr 141B-A35B Powerful Open source LLM
 0:09:49
0:09:49
Install Zephyr 141B-A35B Locally - First ORPO Trained LLM
 0:58:02
0:58:02
Single-Step Language Model Alignment & Smaller-Scale Large Multimodal Models | Multimodal Weekly...
 0:16:38
0:16:38
Fine-Tune LLMs Locally With No Code Using AutoTrain Configs
 0:19:10
0:19:10
Lewis Tunstall - Building Machine Learning Applications using Hugging Face - Uphill Conf 2024
 0:08:42
0:08:42
Comparison: 64mm SSP Multipurpose vs. Niche Zero vs. 64mm SSP High Uniformity
 0:15:08
0:15:08
REI Ruckpack 40 Review | One Bag Travel Backpack (Men’s & Women’s Version)
 1:43:24
1:43:24
1015 Matt Poepsel Full Vice President Predictive Index
 0:56:19
0:56:19
Using Embodied AI to help answer”why” questions in systems neuroscience
 0:57:07
0:57:07
Declarative Learning based Programming for Deep Learning and Reasoning over Natural Language
 4:14:28
4:14:28
TRAITOR LEGIONS - Slaves to Darkness | Warhammer 40k Lore
 2:05:31
2:05:31
Bias in AI panel presentations and Q&A at MIT: 2021 'Unfolding Intelligence' Symposium
Комментарии