filmov
tv
Seri Machine Learning | Python Regresi Linear dengan Scikit - #114
Показать описание
#TutorialBelajar #SeriMachineLearning Supervised Regression Linear
Kali ini kita mau mencoba untuk mengolah data dengan algoritma regresi linear.
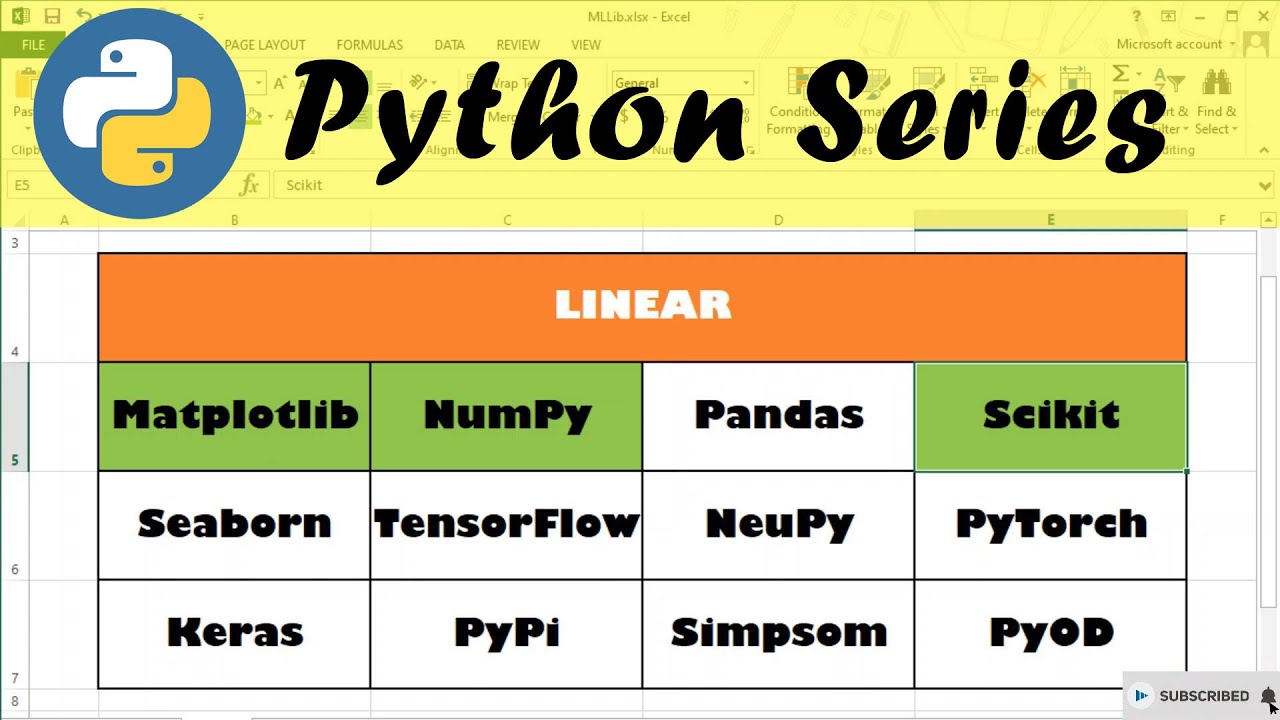
Sekalian kita mau coba 1 lagi library python yg umum digunakan dalam machine learning, yaitu Scikit karena kebetulan library ini belum pernah kita ulas sebelumnya.
Untuk video-video sebelumnya, yang sudah pernah kita pakai adalah library matplotlib, numpy, pandas dan seaborn. Jadi, silakan klik link di atas ini jika kalian pengen liat detilnya.
Lanjut, untuk contoh regresi linear, kita akan gunakan data yang sudah disediakan dari library scikit. Jadi, pertama-tama, kita import dulu library yg mau dipake. Untuk contoh regresi linear ini, kita cukup gunakan 3 saja, yaitu
import numpy as np
#import pandas as pd
from sklearn import datasets, linear_model
Oke, berikutnya... scikit punya utility untuk nge-load dataset.
Bentar, Jadi basic dalam machine-learning dgn sklearn or scikit ini adalah 2 variabel X dan Y.
X itu datanya, sedangkan Y-nya itu label-nya.
Contoh gampangnya: X itu datanya, misal Xnya =[array gambar ferrari, array gambar lamborgini]
sedangkan Y-nya itu label misal Y=[0, 1]
jadi kita melabelkan 0 untuk ferrari, dan 1 untuk lamborgini.
Oke lanjut untuk konteks contoh kita disini, misalnya gini...
Untuk case linear ini, kita gunakan data pasien diabet yg disediain sm scikit.
Jadi ceritanya data ini bersumber dari jurnal kesehatan taon 2002-2003, yang isinya observasi terhadap 442 pasien diabet di sebuah RS. Di data itu ada 10 kolom yg mencatat mulai dari informasi usia, jenis kelamin, BMI, tekanan darah, dll.
Nah, skenarionya aslinya kita mau nguji apakah data yg nanti di test termasuk kedalam kategori orang yang terkena diabet. Cuman, data yg kita pake, ya data yg sama juga. Intinya, yg mau saya share disini adalah konsep berpikir ttg regresi linear nya.
Oke, simpelnya, dari 10 kolom yang ada di data tsb, kita cmn pake 1 kolom aja yang kalo diliat dari aslinya, itu adalah kolom berat badan.
Nah, coba kita liat struktur aslinya via pandas
Sebaiknya, kita ganti aja variabel nya dari X menjadi...
data = pd.DataFrame(data=diabetes_X)
Berikutnya kita akan memisahkan mana data yg mau di train dan mana yg mau di uji coba.
diabetes_X_train = diabetes_X[:-20]
Sebagai contoh, data yang mau di train sebesar 442-20
Dengan alasan semakin besar data yang mau di train, maka akan semakin baik untuk menghasilkan model/pattern.
Lanjut, berikutnya kita akan menyusun data sebanyak 20 untuk diuji.
diabetes_X_test = diabetes_X[-20:]
data = pd.DataFrame(data=diabetes_X_train)
data = pd.DataFrame(data=diabetes_X_test)
Berikutnya, kita akan membuat parameter yg sama untuk menyusun variabel dari label y yg akan kita gunakan. Yaitu label y yg mau di train dan label y yang mau di test.
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
Dari perintah yg sdh kita ketik di atas, hasil dari spliting ini adalah [x_train, x_test, y_train, y_test].
Jadi, prinsipnya bahwa x_train dan y_train akan digunakan sebagai data untuk di training oleh modelnya nanti. Sedangkan x_test dan y_test bisa digunakan sebagai data untuk mengevaluasi model yang sudah di train tadi.
Nah mulai dari baris ini, selanjutnya kita mulai membuat sebuah proses permodelan regresi dengan mengetikkan perintah seperti ini...
regr = linear_model.LinearRegression()
Disini algoritma ML terjadi, kita tidak tahu apa yang dilakukan oleh model tadi, karena dengan model dari sklearn ini, kita hanya terima jadi, tanpa mikir pusing bagaimana kalkulasi yang terjadi didalamnya.
Selanjutnya, sebelum menampilkan hasil, kita coba untuk menyajikan nilai koefisien determinasi atau r2
print('Koef. Determinasi (r2): %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
Nilai r2 mestinya berada di rentang 0 sd 1. Dimana, angka 1 menunjukkan bahwa prediksi model akurat 100% cocok. Sementara untuk angka yg dihasilkan dari ini bahwa tingkat prediksi adalah sebesar ...
Berikutnya, kita coba untuk menampilkan sebaran 2 data yaitu data train dan test dalam bentuk dot scatter yang disandingkan dengan garis linear prediksi dari variabel x test dgn y pred.
Kali ini kita mau mencoba untuk mengolah data dengan algoritma regresi linear.
Sekalian kita mau coba 1 lagi library python yg umum digunakan dalam machine learning, yaitu Scikit karena kebetulan library ini belum pernah kita ulas sebelumnya.
Untuk video-video sebelumnya, yang sudah pernah kita pakai adalah library matplotlib, numpy, pandas dan seaborn. Jadi, silakan klik link di atas ini jika kalian pengen liat detilnya.
Lanjut, untuk contoh regresi linear, kita akan gunakan data yang sudah disediakan dari library scikit. Jadi, pertama-tama, kita import dulu library yg mau dipake. Untuk contoh regresi linear ini, kita cukup gunakan 3 saja, yaitu
import numpy as np
#import pandas as pd
from sklearn import datasets, linear_model
Oke, berikutnya... scikit punya utility untuk nge-load dataset.
Bentar, Jadi basic dalam machine-learning dgn sklearn or scikit ini adalah 2 variabel X dan Y.
X itu datanya, sedangkan Y-nya itu label-nya.
Contoh gampangnya: X itu datanya, misal Xnya =[array gambar ferrari, array gambar lamborgini]
sedangkan Y-nya itu label misal Y=[0, 1]
jadi kita melabelkan 0 untuk ferrari, dan 1 untuk lamborgini.
Oke lanjut untuk konteks contoh kita disini, misalnya gini...
Untuk case linear ini, kita gunakan data pasien diabet yg disediain sm scikit.
Jadi ceritanya data ini bersumber dari jurnal kesehatan taon 2002-2003, yang isinya observasi terhadap 442 pasien diabet di sebuah RS. Di data itu ada 10 kolom yg mencatat mulai dari informasi usia, jenis kelamin, BMI, tekanan darah, dll.
Nah, skenarionya aslinya kita mau nguji apakah data yg nanti di test termasuk kedalam kategori orang yang terkena diabet. Cuman, data yg kita pake, ya data yg sama juga. Intinya, yg mau saya share disini adalah konsep berpikir ttg regresi linear nya.
Oke, simpelnya, dari 10 kolom yang ada di data tsb, kita cmn pake 1 kolom aja yang kalo diliat dari aslinya, itu adalah kolom berat badan.
Nah, coba kita liat struktur aslinya via pandas
Sebaiknya, kita ganti aja variabel nya dari X menjadi...
data = pd.DataFrame(data=diabetes_X)
Berikutnya kita akan memisahkan mana data yg mau di train dan mana yg mau di uji coba.
diabetes_X_train = diabetes_X[:-20]
Sebagai contoh, data yang mau di train sebesar 442-20
Dengan alasan semakin besar data yang mau di train, maka akan semakin baik untuk menghasilkan model/pattern.
Lanjut, berikutnya kita akan menyusun data sebanyak 20 untuk diuji.
diabetes_X_test = diabetes_X[-20:]
data = pd.DataFrame(data=diabetes_X_train)
data = pd.DataFrame(data=diabetes_X_test)
Berikutnya, kita akan membuat parameter yg sama untuk menyusun variabel dari label y yg akan kita gunakan. Yaitu label y yg mau di train dan label y yang mau di test.
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
Dari perintah yg sdh kita ketik di atas, hasil dari spliting ini adalah [x_train, x_test, y_train, y_test].
Jadi, prinsipnya bahwa x_train dan y_train akan digunakan sebagai data untuk di training oleh modelnya nanti. Sedangkan x_test dan y_test bisa digunakan sebagai data untuk mengevaluasi model yang sudah di train tadi.
Nah mulai dari baris ini, selanjutnya kita mulai membuat sebuah proses permodelan regresi dengan mengetikkan perintah seperti ini...
regr = linear_model.LinearRegression()
Disini algoritma ML terjadi, kita tidak tahu apa yang dilakukan oleh model tadi, karena dengan model dari sklearn ini, kita hanya terima jadi, tanpa mikir pusing bagaimana kalkulasi yang terjadi didalamnya.
Selanjutnya, sebelum menampilkan hasil, kita coba untuk menyajikan nilai koefisien determinasi atau r2
print('Koef. Determinasi (r2): %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
Nilai r2 mestinya berada di rentang 0 sd 1. Dimana, angka 1 menunjukkan bahwa prediksi model akurat 100% cocok. Sementara untuk angka yg dihasilkan dari ini bahwa tingkat prediksi adalah sebesar ...
Berikutnya, kita coba untuk menampilkan sebaran 2 data yaitu data train dan test dalam bentuk dot scatter yang disandingkan dengan garis linear prediksi dari variabel x test dgn y pred.
 0:34:34
0:34:34
 0:26:53
0:26:53
 0:15:32
0:15:32
 0:16:01
0:16:01
 0:00:36
0:00:36
 0:23:57
0:23:57
 0:22:15
0:22:15
 0:23:09
0:23:09
 0:29:15
0:29:15
 0:15:45
0:15:45
 0:31:27
0:31:27
 0:07:52
0:07:52
 0:04:05
0:04:05
 0:08:48
0:08:48
 0:34:02
0:34:02
 0:06:51
0:06:51
 0:04:30
0:04:30
 0:00:21
0:00:21
 0:00:31
0:00:31
 0:06:52
0:06:52
 0:00:16
0:00:16
 0:57:52
0:57:52
 0:00:29
0:00:29
 0:24:05
0:24:05