filmov
tv
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Показать описание
This paper shows that the original BERT model, if trained correctly, can outperform all of the improvements that have been proposed lately, raising questions about the necessity and reasoning behind these.
Abstract:
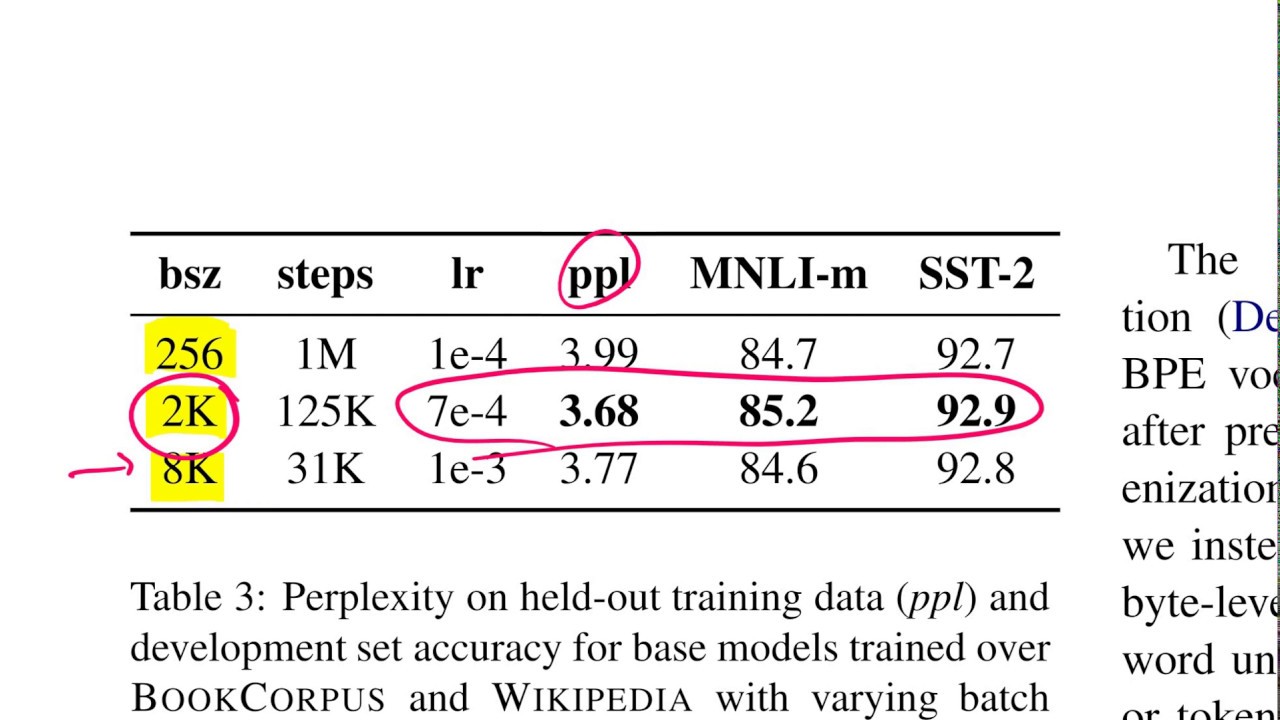
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Authors: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
Abstract:
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Authors: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
 0:19:15
0:19:15
RoBERTa: A Robustly Optimized BERT Pretraining Approach
![[DS Interface] RoBERTa:](https://i.ytimg.com/vi/s8Mv6QsU6zk/hqdefault.jpg) 0:16:47
0:16:47
[DS Interface] RoBERTa: A Robustly Optimized BERT Pretraining Approach
 0:14:37
0:14:37
RoBERTa | Lecture 54 (Part 1) | Applied Deep Learning (Supplementary)
 0:06:32
0:06:32
RoBERTa | Stanford CS224U Natural Language Understanding | Spring 2021
 0:08:55
0:08:55
RoBERTa Explained | Emotion Detection (Hugginface & Python)
 0:03:40
0:03:40
ROBERTA model tutorial | machine learning | deep learning | transformer models | NLP models
 0:29:53
0:29:53
Hugging Face Transformers: the basics. Practical coding guides SE1E1. NLP Models (BERT/RoBERTa)
 0:03:34
0:03:34
NLP Showdown: GPT-4 vs BERT vs RoBERTa vs T5 - Which AI Tool Reigns Supreme?
 0:27:18
0:27:18
Unveiling RoBERTa: Revolutionizing NLP with Advanced Training Techniques
 0:42:49
0:42:49
Transformer, BERT, Roberta and Bart Quick Explanation
 0:07:37
0:07:37
Question Answering with Roberta and MLM
![[DMQA Open Seminar]](https://i.ytimg.com/vi/L_NpC0qcDkM/hqdefault.jpg) 1:01:40
1:01:40
[DMQA Open Seminar] Beyond BERT
 0:12:30
0:12:30
Large Language Model (LLM/NLP) : RoBERTA vs. BERT vs. XLNet for Word Prediction
 1:16:24
1:16:24
Multi-Label Classification on Unhealthy Comments - Finetuning RoBERTa with PyTorch - Coding Tutorial
 0:50:11
0:50:11
Calvin Proposal NLP
 0:15:53
0:15:53
How to train & deploy transformer models (BERT, RoBERTa, XLNet, etc.) without writing any code!
 0:01:03
0:01:03
Most powerful NLP Language models in 2022
 0:05:19
0:05:19
Large Language Models: GPT, ChatGPT, BERT & Other LLM Breakthroughs!
 0:09:18
0:09:18
XLM-RoBERTa | Lecture 56 (Part 2) | Applied Deep Learning (Supplementary)
 1:02:46
1:02:46
Transfer Learning - Similarity detection from contradicting sentences and Roberta
 0:52:25
0:52:25
Pre-trained Transformers: BERT and RoBERTa
 0:11:29
0:11:29
Multilingual BERT - Part 1 - Intro and Concepts
 0:08:52
0:08:52
ALBERT (BERT) model in NLP explained
 1:20:12
1:20:12
Alternative for non-english NLP: XLM-RoBERTa - AI Suisse | Apr 2020
Комментарии