filmov
tv
Stacking Ensemble Learning|Stacking and Blending in ensemble machine learning

Показать описание
Stacking Ensemble Learning|Stacking and Blending in ensemble machine learning
#StackingEnsemble #StackingandBlending #unfolddatascience
Welcome! I'm Aman, a Data Scientist & AI Mentor.
🚀 **Level Up Your Skills:**
* **Udemy Courses:** 🔥 **Start Learning Now!** 🔥
* X (Twitter): @unfolds
* Instagram: @unfold_data_science
🎬 **Featured Playlists:**
🎥 **My Studio Gear:**
#DataScience #AI #MachineLearning
About this video:
In this video I explain the concepts of stacking and blending in ensemble learning. I discuss in detail the working methodology of stacking and blending in ensemble machine learning. Below topics are mentioned in this video:
1. What is stacking ensemble learning
2. Stacking and blending in machine learning
3. Stacking ensemble learning in python
4. What is meta classifier in stacking ensemble
5. Stacking meta classifier explanation
#StackingEnsemble #StackingandBlending #unfolddatascience
Welcome! I'm Aman, a Data Scientist & AI Mentor.
🚀 **Level Up Your Skills:**
* **Udemy Courses:** 🔥 **Start Learning Now!** 🔥
* X (Twitter): @unfolds
* Instagram: @unfold_data_science
🎬 **Featured Playlists:**
🎥 **My Studio Gear:**
#DataScience #AI #MachineLearning
About this video:
In this video I explain the concepts of stacking and blending in ensemble learning. I discuss in detail the working methodology of stacking and blending in ensemble machine learning. Below topics are mentioned in this video:
1. What is stacking ensemble learning
2. Stacking and blending in machine learning
3. Stacking ensemble learning in python
4. What is meta classifier in stacking ensemble
5. Stacking meta classifier explanation
 0:09:26
0:09:26
Stacking Ensemble Learning|Stacking and Blending in ensemble machine learning
 0:08:02
0:08:02
Ensemble (Boosting, Bagging, and Stacking) in Machine Learning: Easy Explanation for Data Scientists
 0:35:20
0:35:20
Stacking and Blending Ensembles
 0:17:39
0:17:39
Stacking Explained for Beginners - Ensemble Learning
 0:03:22
0:03:22
Hands-On Stacking and Blending Algorithm Implementation | Ensemble Machine Learning Algorithms
 0:03:47
0:03:47
Ensemble Learning - Bagging, Boosting, and Stacking explained in 4 minutes!
 0:03:59
0:03:59
Ensemble Machine Learning Techniques: Overview of Stacking Technique|packtpub.com
 0:01:11
0:01:11
Stacking (blending)
 0:07:53
0:07:53
Ensemble Machine Learning Technique: Blending & Stacking
 0:04:51
0:04:51
59 Stacking, Blending - Advanced Ensemble Learning Algorithms
 0:00:33
0:00:33
Stacking in Ensemble Learning: The Ultimate Model Fusion!
 0:03:12
0:03:12
stacking and blending ensembles
 0:25:42
0:25:42
#12 ( Stacking Ensemble Learning ) || Section - 9 || Ensemble Learning
 0:04:32
0:04:32
Ensemble Learning Method Machine Learning Stacking
 0:07:22
0:07:22
What is a Ensemble Model? (Stacking)
 0:08:37
0:08:37
Ensemble Learning Techniques Voting Bagging Boosting Random Forest Stacking in ML by Mahesh Huddar
 0:11:00
0:11:00
Understanding Ensemble Models | Stacking Models | Blending | Meta Model
 0:13:14
0:13:14
Ensemble Method: Stacking (Stacked Generalization)
 1:16:18
1:16:18
Ensembling, Blending & Stacking
 0:12:51
0:12:51
Ensemble Learning pour les Débutants : Bagging, Boosting et Stacking Démystifié
 0:12:28
0:12:28
Boosting | Stacking | Ensemble Learning Part-10 | Machine Learning Tutorial - InsideAIML
 0:48:49
0:48:49
Machine Learning Course - 16. Ensembles 3: Stacking & Intelligence Architectures
 0:06:47
0:06:47
Stacking Ensemble in Python
 0:34:13
0:34:13
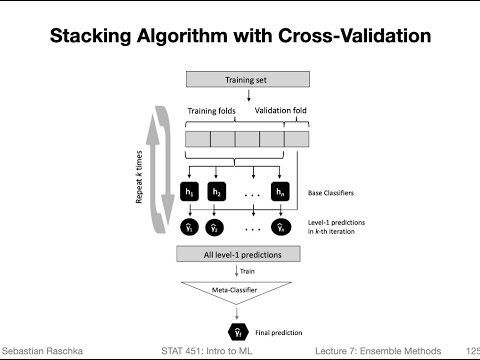
7.7 Stacking (L07: Ensemble Methods)
Комментарии