filmov
tv
All Convolution Animations Are Wrong (Neural Networks)

Показать описание
All the neural network 2d convolution animations you've seen are wrong.
 0:04:53
0:04:53
All Convolution Animations Are Wrong (Neural Networks)
 0:09:01
0:09:01
Source of confusion! Neural Nets vs Image Processing Convolution
 0:00:49
0:00:49
Convolution animation manim
 0:05:55
0:05:55
Kernel Size and Why Everyone Loves 3x3 - Neural Network Convolution
 0:00:28
0:00:28
neural networks animation
 0:01:38
0:01:38
2D Convolution Neural Network Animation
 0:07:25
0:07:25
Convolution Explainer (Animation)
 0:10:47
0:10:47
Convolutional Neural Networks Explained (CNN Visualized)
 0:16:30
0:16:30
Why do Convolutional Neural Networks work so well?
 0:05:18
0:05:18
Fundamental Algorithm of Convolution in Neural Networks
 0:06:09
0:06:09
Groups, Depthwise, and Depthwise-Separable Convolution (Neural Networks)
 0:05:55
0:05:55
AI CNN Convolution Animation, AI instructional videos, Neural Networks, Deep Learning Python, L2
 0:08:39
0:08:39
Stride - Convolution in Neural Networks
 0:03:34
0:03:34
Convolution Padding - Neural Networks
 0:10:28
0:10:28
Convolutions are not Convoluted
 0:05:20
0:05:20
Filter Count - Convolutional Neural Networks
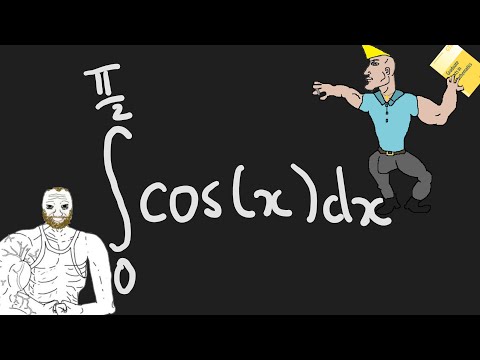 0:00:35
0:00:35
How REAL Men Integrate Functions
 0:00:17
0:00:17
Visualization of a Convolution Neural Network (CNN). Made with Unity 3D and lots of custom code
 0:05:36
0:05:36
What is convolution? This is the easiest way to understand
 0:00:38
0:00:38
Operations in Convolutional Neural Networks | Convolution, Pooling and Fully Connected Layer
 0:06:19
0:06:19
Artificial Intelligence CNN Convolution Animation, AI Neural Networks, Deep Learning Python, L3
 0:05:06
0:05:06
2D Convolution Explained: Fundamental Operation in Computer Vision
 0:01:07
0:01:07
Visualization of a fully connected neural network, version 1
 0:05:23
0:05:23
How to Understand Convolution ('This is an incredible explanation')
Комментарии