filmov
tv
14: Distributed Logging & Metrics Framework | Systems Design Interview Questions With Ex-Google SWE

Показать описание
200 videos and we're still talking about logs - thanks guys, you're the best
 0:28:08
0:28:08
14: Distributed Logging & Metrics Framework | Systems Design Interview Questions With Ex-Google ...
 0:21:32
0:21:32
Distributed Metrics/Logging Design Deep Dive with Google SWE! | Systems Design Interview Question 14
 0:57:37
0:57:37
System Design Mock Interview - Design distributed metrics logging system
 0:14:38
0:14:38
System Design Fundamentals | Pt 10 | Logging, Metrics, Automation, and Monitoring
 0:39:40
0:39:40
Logs, Metrics, and APM: The Holy Trinity of Ops - Thomas Watson
 0:03:17
0:03:17
Effective troubleshooting with Grafana Loki - query basics
 0:44:59
0:44:59
Distributed Logging & Metrics System Design | Microservices Logging | Distributed Systems in Hin...
 0:23:59
0:23:59
7. Observability Coordinated: Prometheus Exemplars (Metrics) — Grafana Tempo (Traces) — Loki (Logs)...
 0:06:14
0:06:14
Top 7 Most-Used Distributed System Patterns
 0:01:36
0:01:36
OpenShift 3.1 Logging & Metrics Overview
 0:10:49
0:10:49
Advanced Techniques for AWS Monitoring, Metrics and Logging
 0:19:13
0:19:13
Task - 14 - GCP | Nodejs App | Cloud Logging | Log Based Metric | Dashboard | Ship to BigQuery
 0:20:18
0:20:18
Fluent Bit 3.0 Observability: Elevating Logs, Metrics, and Traces!
 0:00:58
0:00:58
time and work | time and work tricks | #shorts #short #shortvideo #viral
 0:20:44
0:20:44
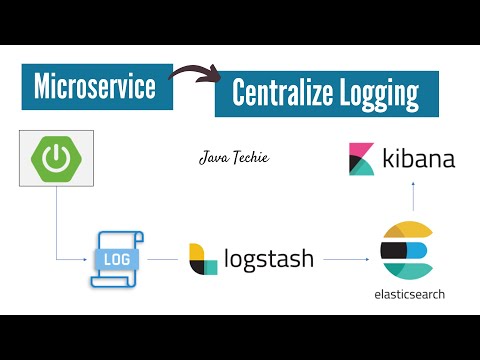
Microservices Logging | ELK Stack | Elastic Search | Logstash | Kibana | JavaTechie
 0:23:03
0:23:03
How to do Structured Logging and Custom Metrics in your Serverless Applications?
 1:08:48
1:08:48
OpenTelemetry Course - Understand Software Performance
 0:13:38
0:13:38
Performance Metrics | System Design Tutorials | Lecture 14 | 2020
 0:56:08
0:56:08
Unified Go-To-Market 14 | GTM Bloat and Financial Metrics in B2B SaaS Companies
 0:19:00
0:19:00
Monitoring baseline on k3d: logs, metrics, ingress and testing the Linkerd service mesh
 0:21:31
0:21:31
How Prometheus Monitoring works | Prometheus Architecture explained
 1:32:53
1:32:53
Design a metrics monitoring system
 0:03:36
0:03:36
Unified Logs and Metrics Demo
 0:27:22
0:27:22
SREcon21 - Taking Control of Metrics Growth and Cardinality: Tips for Maximizing Your Observability
Комментарии