filmov
tv
AWS Glue: Read CSV Files From AWS S3 Without Glue Catalog

Показать описание
This video is about how to read in data files stored in csv in AWS S3 in AWS Glue when your data is not defined in the AWS Glue Catalog. This video uses the create_dynamic_frame_from_options method
#aws, #awsglue
#aws, #awsglue
 0:05:05
0:05:05
AWS Glue: Read CSV Files From AWS S3 Without Glue Catalog
 0:02:28
0:02:28
AWS: How to use AWS Glue ETL to convert CSV to Parquet - Tutorial
 0:20:09
0:20:09
AWS Tutorials - When to use Custom CSV Glue Classifier?
 0:15:31
0:15:31
How to import CSV file from Amazon S3 to Redshift using AWS Glue Jobs
 0:16:25
0:16:25
AWS Glue - Serverless Data Integration Service - S3 csv to Parquet Transformation - Part1
 0:17:04
0:17:04
Importing CSV files from S3 into Redshift with AWS Glue
 0:02:37
0:02:37
AWS Glue: ETL to read S3 CSV files (2 Solutions!!)
 0:07:51
0:07:51
AWS Glue PySpark: Flatten Nested Schema (JSON)
 0:06:54
0:06:54
import data from S3 to RDS using AWS Glue
 0:25:37
0:25:37
AWS Glue custom classifier | CSV | AWS Glue tutorial | p7
 0:15:30
0:15:30
Transforming a CSV file to Parquett in minutes using AWS Glue
 0:28:24
0:28:24
AWS Glue | Importing CSV files from S3 into Redshift
 0:13:47
0:13:47
AWS Glue Data Catalog | Glue Database, Crawler, Connections, Classifiers explained | Glue tutorial-2
 0:07:31
0:07:31
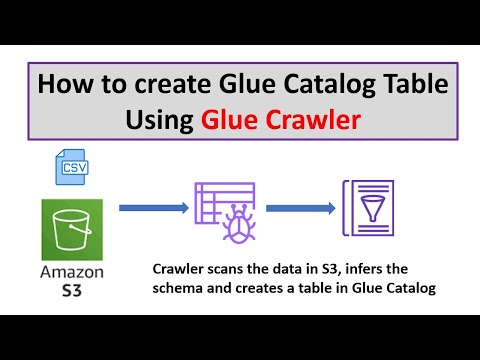
How to create table in AWS Glue Catalog using Crawler | AWS Glue Tutorials | Hands-on tutorial
 0:16:31
0:16:31
14. AWS Glue Practical | AWS Glue CSV to JSON | AWS Data Engineer
 0:13:07
0:13:07
Converting Small Files into Large Files in AWS Glue Python
 0:08:23
0:08:23
AWS Glue: Write Parquet With Partitions to AWS S3
 0:04:10
0:04:10
Load a CSV file into AWS Athena for SQL Analysis
 0:37:55
0:37:55
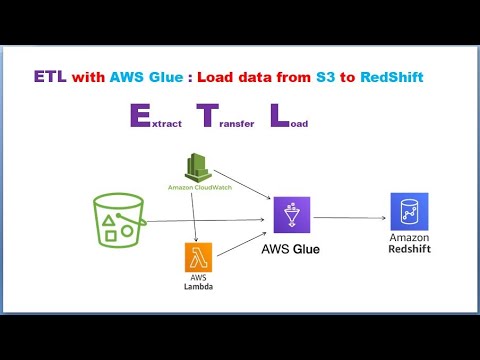
ETL | AWS Glue | AWS S3 | Load Data from AWS S3 to Amazon RedShift
 0:25:17
0:25:17
Joining Files with AWS Glue
 0:56:45
0:56:45
Engineering CSV files from S3 To Redshift using AWS Glue Crawlers!
 0:06:43
0:06:43
CSV - S3 - GLUE - ATHENA Interfacing
 0:41:30
0:41:30
AWS Glue Tutorial for Beginners [FULL COURSE in 45 mins]
 0:15:45
0:15:45
Create Partitioned Table AWS Glue From simple CSV file with 1M records | New Glue 3.0 UI
Комментарии