filmov
tv
Python Automation Series #9 : How to extract a page from a PDF file with Python ?

Показать описание
PDF documents are binary files, which makes them much more complex than plaintext files.
In addition to text, they store font, color and layout information.
PyPDF2 does not have a way to extract images, charts or other media from PDF documents, but it can extract text and return it as a Python string.
In addition to text, they store font, color and layout information.
PyPDF2 does not have a way to extract images, charts or other media from PDF documents, but it can extract text and return it as a Python string.
 0:06:07
0:06:07
Python Automation Series #9 : How to extract a page from a PDF file with Python ?
 0:21:38
0:21:38
Selenium Browser Automation in Python
 0:11:26
0:11:26
Automating My Life with Python: The Ultimate Guide | Code With Me
 0:13:17
0:13:17
Python Automation | Part 9 : WhatsApp Automation | No QR Code | Python Selenium Web Automation
 1:16:38
1:16:38
Session 9- Python Programming for Selenium
 0:17:00
0:17:00
3 PYTHON AUTOMATION PROJECTS FOR BEGINNERS
 0:18:40
0:18:40
5 Amazing Ways to Automate Your Life using Python
 2:42:55
2:42:55
Automate with Python – Full Course for Beginners
 1:47:31
1:47:31
Mock Interviews for Software QA and Test Engineers
 6:14:07
6:14:07
Python Tutorial - Python Full Course for Beginners
 0:15:30
0:15:30
How I AUTOMATE my FINANCES USING PYTHON
 1:14:05
1:14:05
Python Automation with ChatGPT
 1:00:06
1:00:06
Python for Beginners - Learn Python in 1 Hour
 0:24:10
0:24:10
Using Python to Automate AWS Services | Lambda and EC2
 0:00:28
0:00:28
Developer Last Expression 😂 #shorts #developer #ytshorts #uiux #python #flutterdevelopment
 0:00:59
0:00:59
Create a Spiderman using python coding |python programer| #tech #python #coding
 0:14:07
0:14:07
Automated Video Editing with MoviePy in Python
 0:15:33
0:15:33
3 PYTHON AUTOMATION PROJECTS FOR BEGINNERS (Make Money Coding)
 0:00:28
0:00:28
How to hide user input in Python
 0:00:45
0:00:45
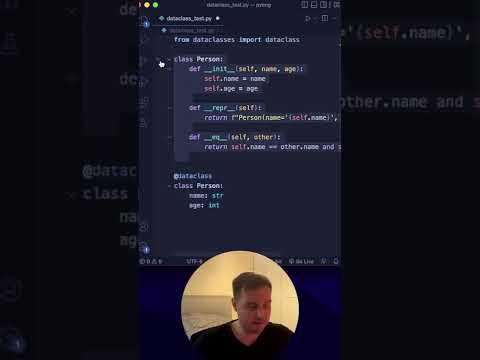
Why dataclasses in Python are awesome!
 0:00:52
0:00:52
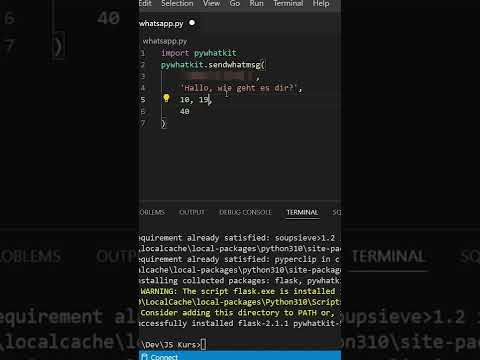
WhatsApp Bot #coden #python #libary #whatsapp
 0:33:00
0:33:00
Python Automation Tutorial | Python Automation Projects | Python Certification Training | Edureka
 0:12:21
0:12:21
Lesson 9 - Python Programming (Automate the Boring Stuff with Python)
 1:03:21
1:03:21
👩💻 Python for Beginners Tutorial
Комментарии