filmov
tv
Web Scraping with GPT-4 Vision AI + Puppeteer is Mind-Blowingly EASY!

Показать описание
👉 Discord: all my courses have a private Discord where I actively participate
⏱️ Timestamps:
00:00 Intro
00:48 ChatGPT for HTML
02:01 OpenAI API
04:08 Puppeteer
04:28 Avoid restrictions (Bright Data)
05:11 Get HTML with Puppeteer + Proxy
08:35 Processing HTML
10:00 Give HTML to OpenAI
12:19 ChatGPT for scraper code
14:41 Vision API
19:40 Vision API pricing
21:12 Vision vs Text pricing
22:52 Future of web scraping (AI + Bright Data)
#webdevelopment #programming #coding #reactjs #nextjs
 0:13:06
0:13:06
WEB SCRAPPING Using CHATGPT | How To Use GPT 4 Vision API To Automate Web Scrapping | Simplilearn
 0:07:36
0:07:36
Vision-based Web Scraping with the New GPT-4o model
 0:24:14
0:24:14
Web Scraping with GPT-4 Vision AI + Puppeteer is Mind-Blowingly EASY!
 0:56:25
0:56:25
GPT-4 Vision API + Puppeteer = Easy Web Scraping
 0:24:48
0:24:48
GPT4V + Puppeteer = AI agent browse web like human? 🤖
 0:12:12
0:12:12
Will AI Kill Traditional Web Scraping? (GPT4V + Mistral Medium Project)
 0:09:30
0:09:30
Automating Web Scraping with GPT-4
 0:13:54
0:13:54
Vision-based Web Scraping with the New GPT-4o model in Make.com
 0:10:40
0:10:40
Scrape Anything with GPT-4o (Vision Based Scraping)
 0:20:02
0:20:02
5 Use Cases for GPT-4 Vision API (and DALL-E 3)
 0:06:17
0:06:17
Industrial-scale Web Scraping with AI & Proxy Networks
 0:05:28
0:05:28
ChatGPT Plugin Review: Scraper AI. Grab information from webpages in seconds.
 0:11:11
0:11:11
Scrape ANY Website for FREE USING GPT-4o Vision | LLM Project
 0:00:59
0:00:59
GPT-4 Vision API+Puppeteer=Easy Web Scraping#airevolution #technology #artificialintelligence #ai
 0:12:51
0:12:51
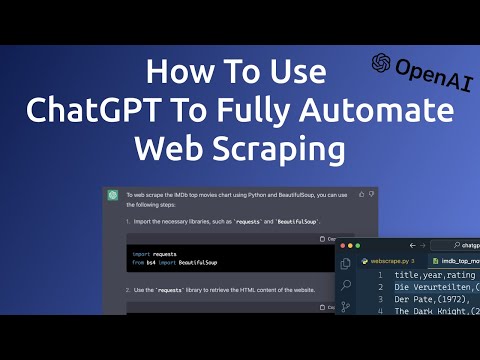
How To Use ChatGPT To Fully Automate Web Scraping
 0:05:09
0:05:09
Scrape Any Website with GPT4, Here's How
 0:08:03
0:08:03
Web Scraping with ChatGPT is mind blowing 🤯
 0:06:04
0:06:04
Scrape ANY Website with AI For Free | Best AI Tools
 0:07:40
0:07:40
NEW Use GPT-4o To Scrape Websites & Get More Clients!
 0:00:31
0:00:31
New Tutorial: extract info from any website using no-code and Open AI's Vision. #nocode #scrapi...
 0:08:27
0:08:27
How To Install LLaVA 👀 Open-Source and FREE 'ChatGPT Vision'
 0:24:10
0:24:10
Scrape any website with OpenAI Functions & LangChain
 0:26:22
0:26:22
Vision Based Web Scraping with GPT 4o | Make.com | Scrapingbee | AI Automation
 0:08:07
0:08:07
GPT-4 Vision + Zapier + MindStudio (INSANE Automations)
Комментарии