filmov
tv
Optimization Techniques - W2023 - Lecture 7 (Backpropagation, AGM, SGD, SAG, Adam, Neural Networks)

Показать описание
The course "Optimization Techniques" (ENGG*6140, section 2) at the School of Engineering at the University of Guelph. Instructor: Benyamin Ghojogh
Lecture 7 continues the first-order optimization methods after the introduction of gradient descent in previous session. We start with momentum and steepest descent. Then, the backpropagation algorithm is explained for training neural networks. Afterwards, we cover Nesterov's Accelerated Gradient Method (AGM). Then, we cover the stochastic gradient methods including Stochastic Gradient Descent (SGD) and mini-batch SGD. Thereafter, we cover stochastic average gradient methods including Stochastic Average Gradient (SAG) and Stochastic Variance Reduced Gradient (SVRG). Then, adaptive learning rate algorithms are introduced including Adaptive Gradient (AdaGrad), Root Mean Square Propagation (RMSProp), and Adaptive Moment Estimation (Adam) optimizer. Finally, we code a feedforward neural network using the PyTorch library in Python.
Some part of this lecture was inspired by the lectures of Prof. Kimon Fountoulakis at the University of Waterloo.
The backpropagation part of this lecture is inspired by the lectures of Prof. Ali Ghodsi at the University of Waterloo:
Chapters:
0:00 - Talking about course project
4:03 - Talking about the midterm exam
7:38 - Talking about my courses in summer 2023
17:02 - Momentum
21:55 - Steepest descent
27:18 - Backpropagation
51:35 - Accelerated Gradient Method (AGM)
1:08:31 - Stochastic Gradient Descent (SGD)
1:29:07 - Mini-batch Stochastic Gradient Descent
1:39:34 - Stochastic Average Gradient (SAG)
1:44:21 - Stochastic Variance Reduced Gradient (SVRG)
1:45:28 - Adaptive Gradient (AdaGrad)
1:53:24 - Root Mean Square Propagation (RMSProp)
1:56:51 - Adaptive Moment Estimation (Adam)
2:00:37 - Coding a neural network with PyTorch in Python
2:06:28 - Object-oriented programming (explaining by Plato's theory of Ideas)
2:11:26 - Continuing coding a neural network
Lecture 7 continues the first-order optimization methods after the introduction of gradient descent in previous session. We start with momentum and steepest descent. Then, the backpropagation algorithm is explained for training neural networks. Afterwards, we cover Nesterov's Accelerated Gradient Method (AGM). Then, we cover the stochastic gradient methods including Stochastic Gradient Descent (SGD) and mini-batch SGD. Thereafter, we cover stochastic average gradient methods including Stochastic Average Gradient (SAG) and Stochastic Variance Reduced Gradient (SVRG). Then, adaptive learning rate algorithms are introduced including Adaptive Gradient (AdaGrad), Root Mean Square Propagation (RMSProp), and Adaptive Moment Estimation (Adam) optimizer. Finally, we code a feedforward neural network using the PyTorch library in Python.
Some part of this lecture was inspired by the lectures of Prof. Kimon Fountoulakis at the University of Waterloo.
The backpropagation part of this lecture is inspired by the lectures of Prof. Ali Ghodsi at the University of Waterloo:
Chapters:
0:00 - Talking about course project
4:03 - Talking about the midterm exam
7:38 - Talking about my courses in summer 2023
17:02 - Momentum
21:55 - Steepest descent
27:18 - Backpropagation
51:35 - Accelerated Gradient Method (AGM)
1:08:31 - Stochastic Gradient Descent (SGD)
1:29:07 - Mini-batch Stochastic Gradient Descent
1:39:34 - Stochastic Average Gradient (SAG)
1:44:21 - Stochastic Variance Reduced Gradient (SVRG)
1:45:28 - Adaptive Gradient (AdaGrad)
1:53:24 - Root Mean Square Propagation (RMSProp)
1:56:51 - Adaptive Moment Estimation (Adam)
2:00:37 - Coding a neural network with PyTorch in Python
2:06:28 - Object-oriented programming (explaining by Plato's theory of Ideas)
2:11:26 - Continuing coding a neural network
 1:47:38
1:47:38
 0:00:05
0:00:05
 0:25:43
0:25:43
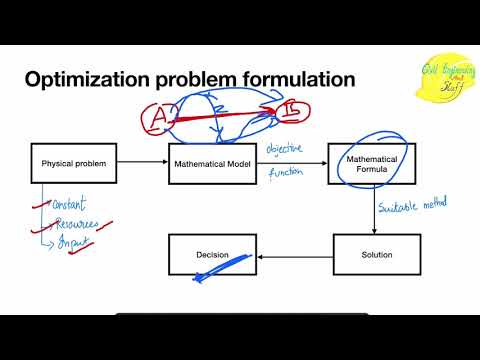 0:23:10
0:23:10
 0:11:00
0:11:00
 0:05:05
0:05:05
 0:12:39
0:12:39
 0:00:30
0:00:30
 0:21:51
0:21:51
 0:00:41
0:00:41
 0:10:45
0:10:45
 0:13:36
0:13:36
 0:18:50
0:18:50
 0:37:55
0:37:55
 0:40:25
0:40:25
 0:19:40
0:19:40
 0:51:17
0:51:17
 0:54:25
0:54:25
 0:01:01
0:01:01
 0:19:21
0:19:21
 0:08:41
0:08:41
 0:15:58
0:15:58
 0:06:51
0:06:51
 0:41:58
0:41:58