filmov
tv
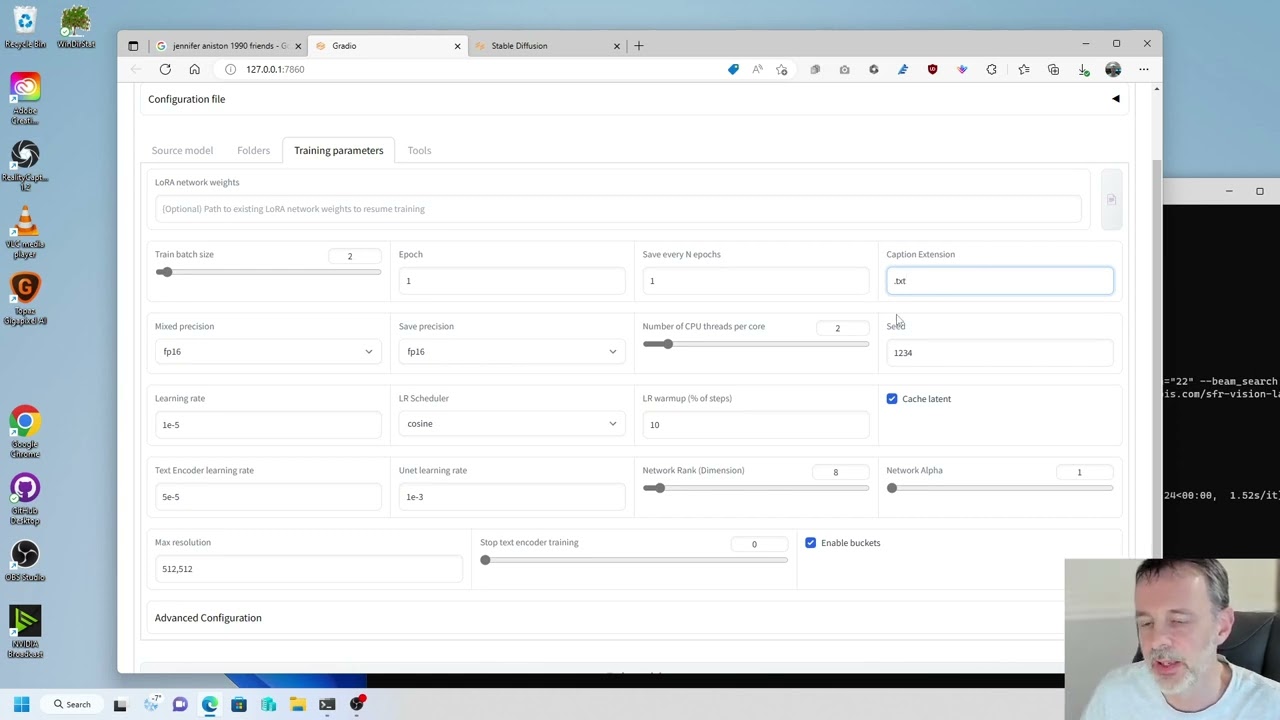
Creating a LoRA weight using kohya_ss GUI, part 2: Training the model and creating outputs
Показать описание
This is the part two of creating a LoRA weight. It will explain how you go about creating your model and generating realistic outputs from prompts.
 0:45:12
0:45:12
Creating a LoRA weight using kohya_ss GUI, part 1: Dataset creation and preparation
 0:40:37
0:40:37
Creating a LoRA weight using kohya_ss GUI, part 2: Training the model and creating outputs
 0:03:04
0:03:04
How to Train Your Own AI Model (LoRA) Using Personal or Favorite Celebrity Photos Without any GPU.
 0:04:38
0:04:38
LoRA - Low-rank Adaption of AI Large Language Models: LoRA and QLoRA Explained Simply
 0:21:14
0:21:14
ULTIMATE FREE LORA Training In Stable Diffusion! Less Than 7GB VRAM!
 0:34:38
0:34:38
LORA + Checkpoint Model Training GUIDE - Get the BEST RESULTS super easy
 0:05:52
0:05:52
Supermachine LORA Tutorial: Control Weight, Hair Length, and More!
 0:05:31
0:05:31
How To Install and Use LoRA Models (Stable Diffusion)
 0:36:20
0:36:20
LORA Training - for HYPER Realistic Results
 0:05:35
0:05:35
ComfyUI-Inspire-Pack - Lora Block Weight
 0:04:08
0:04:08
STOP Using LORA'S, Use THIS Instead || Train Flux Models With Lockr
 0:27:33
0:27:33
LORA training EXPLAINED for beginners
 0:21:01
0:21:01
Intro to LoRA Models: What, Where, and How with Stable Diffusion
 0:38:03
0:38:03
How to fine-tune a model using LoRA (step by step)
 0:08:22
0:08:22
What is LoRA? Low-Rank Adaptation for finetuning LLMs EXPLAINED
 0:14:27
0:14:27
Free FLUX LoRA Training | Easy Ai Influencer LoRA | FluxGym Tutorial
 0:00:57
0:00:57
Digital weigh scale user guide and IoT enablement using LoRa, ESP32
 0:26:55
0:26:55
LoRA: Low-Rank Adaptation of Large Language Models - Explained visually + PyTorch code from scratch
 0:12:07
0:12:07
Explaining Prompting Techniques In 12 Minutes – Stable Diffusion Tutorial (Automatic1111)
 0:40:20
0:40:20
Create Realistic AI Images of YOU with FLUX: Training LoRA Adapters to Generating Images (Free) 2025
 0:15:35
0:15:35
Fine-tuning LLMs with PEFT and LoRA
 0:17:07
0:17:07
LoRA explained (and a bit about precision and quantization)
 0:03:23
0:03:23
Understand PROMPT Formats: (IN 3 Minutes!!)
 0:07:28
0:07:28
Mastering ComfyUI: How to Use Embedding, LoRa and Hypernetworks! - TUTORIAL
Комментарии