filmov
tv
Python Tutorial: Review of pandas DataFrames

Показать описание
---
Let's learn how to get data in and look at it.
We'll need to remember a few things about Pandas first.
Pandas is a library for data analysis.
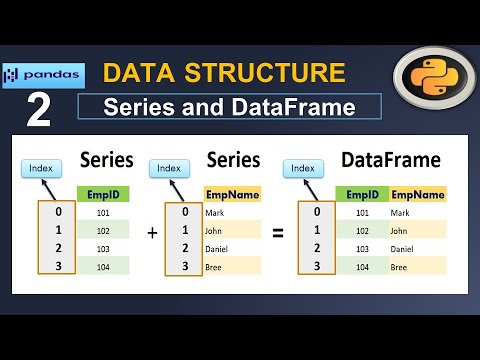
The powertool of Pandas is the DataFrame, a tabular data structure with labeled rows & columns.
As an example, we'll use a DataFrame with Apple stock data.
The rows are labeled by a special data structure called an Index (we'll learn more about Indexes later).
Indexes in Pandas are tailored lists of labels that permit fast look-up and some powerful relational operations.
The index labels in the aapl DataFrame are dates in reverse chronological order.
Labeled rows & columns improves the clarity and intuition of many data analysis tasks.
When we ask for the type of the object AAPL, it's a DataFrame.
When we ask for its shape, it has 8514 rows & 6 columns.
The DataFrame columns attribute gives the names of its columns (Open, High, Low, Close, Volume, and Adjusted Close).
We'll study DatetimeIndexes and time series later.
DataFrames can be sliced like NumPy arrays or Python lists using colons to specify the start, end, and stride of a slice.
First, we can slice from the start of the DataFrame to the 5th row (non-inclusive) using the dot iloc accessor to express the slice positionally.
Second, we can slice from the 5th last row to the end of the DataFrame using a negative index.
Remember, it's also possible to slice using labels with the dot loc accessor.
There's another way to see just the top rows of a DataFrame: the head method.
Specifying head(5) returns the first 5 rows.
Specifying head(2) returns the first 2 rows.
The head() method is particularly useful here because our DataFrame has over 8000 rows.
The opposite of head() is tail().
Specifying tail() without an argument returns the last 5 rows by default.
Specifying tail(3) returns the last 3 rows.
Again, tail() gives a useful summary of a large DataFrames.
Another useful summary method is info.
info returns other useful summary information, including the kind of Index, the column labels, the number of rows & columns, and the datatype of each column.
Pandas DataFrame slices also support broadcasting (we'll learn more about this later).
Here, a slice is assigned a scalar value (in this case, nan or Not a Number).
The slice consists of every third row starting from zero in the last column.
We can call head(6) to see the changes.
We can also call info() and notice the last column has fewer non-null entries than the others due to our assigning nan to every third element.
The columns of a DataFrame are themselves a specialized Pandas structure called a Series.
Extracting a single column from a DataFrame returns a Series.
Notice the Series extracted has its own head() method and inherits its name attribute from the DataFrame column.
To extract the numerical entries from the Series, use the values attribute.
The data in the Series actually form a NumPy array which is what the values attribute yields.
A Pandas Series, then, is a 1D labelled NumPy array and a DataFrame is a 2D labelled array whose columns are Series.
We've seen a few concepts extending what we already knew about including head, tail, info, index, values, and Series.
Take some time to practice using these concepts in the exercises.
#Python #PythonTutorial #DataCamp #pandas #Foundations #DataFrames
 0:04:16
0:04:16
 0:13:31
0:13:31
 0:10:08
0:10:08
 0:23:06
0:23:06
 4:57:59
4:57:59
 0:05:55
0:05:55
 0:15:52
0:15:52
 4:22:13
4:22:13
 2:18:11
2:18:11
 2:30:45
2:30:45
 0:04:28
0:04:28
 0:53:22
0:53:22
 0:01:48
0:01:48
 0:40:22
0:40:22
 0:05:04
0:05:04
 0:04:14
0:04:14
 0:38:45
0:38:45
 0:04:41
0:04:41
 0:03:55
0:03:55
 5:20:18
5:20:18
 0:34:17
0:34:17
 12:19:52
12:19:52
 0:04:21
0:04:21
 0:22:09
0:22:09