filmov
tv
Autoencoders - Ep. 10 (Deep Learning SIMPLIFIED)

Показать описание
Autoencoders are a family of neural nets that are well suited for unsupervised learning, a method for detecting inherent patterns in a data set. These nets can also be used to label the resulting patterns.
Deep Learning TV on
Essentially, autoencoders reconstruct a data set and, in the process, figure out its inherent structure and extract its important features. An RBM is a type of autoencoder that we have previously discussed, but there are several others.
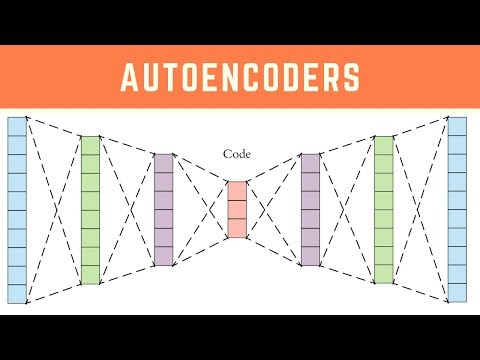
Autoencoders are typically shallow nets, the most common of which have one input layer, one hidden layer, and one output layer. Some nets, like the RBM, have only two layers instead of three. Input signals are encoded along the path to the hidden layer, and these same signals are decoded along the path to the output layer. Like the RBM, the autoencoder can be thought of as a 2-way translator.
Autoencoders are trained with backpropgation and a new concept known as loss. Loss measures the amount of information about the input that was lost through the encoding-decoding process. The lower the loss value, the stronger the net.
Some autoencoders have a very deep structure, with an equal number of layers for both encoding and decoding. A key application for deep autoencoders is dimensionality reduction. For example, these nets can transform a 256x256 pixel image into a representation with only 30 numbers. The image can then be reconstructed with the appropriate weights and bias; as an addition, some nets also add random noise at this stage in order to enhance the robustness of the discovered patterns. The reconstructed image wouldn’t be perfect, but the result would be a decent approximation depending on the strength of the net. The purpose of this compression is to the reduce the input size on a set of data before feeding it to a deep classifier. Smaller inputs lead to large computational speedups, so this preprocessing step is worth the effort.
Have you ever used an autoencoder to reduce the dimensionality of your data? Please comment and share your experiences.
Deep autoencoders are much more powerful than their predecessor, principal component analysis. In the video, you'll see the comparison of two letter codes associated with news stories of different topics. Among the two models, you’ll find the deep autoencoder to be far superior.
Credits
Nickey Pickorita (YouTube art) -
Isabel Descutner (Voice) -
Dan Partynski (Copy Editing) -
Marek Scibior (Prezi creator) -
Jagannath Rajagopal (Creator, Producer and Director) -
Deep Learning TV on
Essentially, autoencoders reconstruct a data set and, in the process, figure out its inherent structure and extract its important features. An RBM is a type of autoencoder that we have previously discussed, but there are several others.
Autoencoders are typically shallow nets, the most common of which have one input layer, one hidden layer, and one output layer. Some nets, like the RBM, have only two layers instead of three. Input signals are encoded along the path to the hidden layer, and these same signals are decoded along the path to the output layer. Like the RBM, the autoencoder can be thought of as a 2-way translator.
Autoencoders are trained with backpropgation and a new concept known as loss. Loss measures the amount of information about the input that was lost through the encoding-decoding process. The lower the loss value, the stronger the net.
Some autoencoders have a very deep structure, with an equal number of layers for both encoding and decoding. A key application for deep autoencoders is dimensionality reduction. For example, these nets can transform a 256x256 pixel image into a representation with only 30 numbers. The image can then be reconstructed with the appropriate weights and bias; as an addition, some nets also add random noise at this stage in order to enhance the robustness of the discovered patterns. The reconstructed image wouldn’t be perfect, but the result would be a decent approximation depending on the strength of the net. The purpose of this compression is to the reduce the input size on a set of data before feeding it to a deep classifier. Smaller inputs lead to large computational speedups, so this preprocessing step is worth the effort.
Have you ever used an autoencoder to reduce the dimensionality of your data? Please comment and share your experiences.
Deep autoencoders are much more powerful than their predecessor, principal component analysis. In the video, you'll see the comparison of two letter codes associated with news stories of different topics. Among the two models, you’ll find the deep autoencoder to be far superior.
Credits
Nickey Pickorita (YouTube art) -
Isabel Descutner (Voice) -
Dan Partynski (Copy Editing) -
Marek Scibior (Prezi creator) -
Jagannath Rajagopal (Creator, Producer and Director) -
 0:03:52
0:03:52
Autoencoders - Ep. 10 (Deep Learning SIMPLIFIED)
 0:02:12
0:02:12
AnalyticsX: Autoencoders
 0:15:05
0:15:05
Variational Autoencoders
 0:10:53
0:10:53
Autoencoders - EXPLAINED
 0:10:31
0:10:31
Simple Explanation of AutoEncoders
 0:04:51
0:04:51
Autoencoders explained — The unsung heroes of the AI world!
 0:03:50
0:03:50
What is an Autoencoder? | Two Minute Papers #86
 0:09:19
0:09:19
Autoencoders - Denoise and Compress Data
 0:23:58
0:23:58
Autoencoders Tutorial | Autoencoders In Deep Learning | Tensorflow Training | Edureka
 0:12:29
0:12:29
Autoencoders Made Simple!
 0:13:12
0:13:12
4. Autoencoders
 0:01:17
0:01:17
Extraction and Interpretation of Deep Autoencoder-based Temporal Features from Wearables...
 0:07:44
0:07:44
Neuronale Netze #23 - Autoencoder (Machine Learning #103)
 0:28:20
0:28:20
235 - Pre-training U-net using autoencoders - Part 1 - Autoencoders and visualizing features
 0:36:50
0:36:50
PyData Tel Aviv Meetup: Generative models And Variational AutoEncoder explained - Shai Harel
 0:00:12
0:00:12
Deep Convolutional Denoising Autoencoder for Image Classification
 0:14:43
0:14:43
Losses In Neural Networks | Complete Deep Learning Course|Episode- 10 #deeplearning #datascience #ai
 0:09:13
0:09:13
MLVU 9.3: Autoencoders
 0:01:56
0:01:56
Unsupervised Deep Learning in Python: PCA, t-SNE, Autoencoders, RBM Intro
 0:05:00
0:05:00
3D Shape Variational Autoencoder Latent Disentanglement via Mini Batch Feature Swapping | CVPR 2022
 0:08:40
0:08:40
Deep Learning Projects with PyTorch : Introduction to Autoencoders | packtpub.com
 0:44:15
0:44:15
Autoencoders - Deep Learning Nodes
 0:03:10
0:03:10
Introduction to DeepLearning Autoencoders
 0:03:15
0:03:15
Learning Motion Manifolds with Convolutional Autoencoders
Комментарии