filmov
tv
R Tutorial: Parallel Programming in R

Показать описание
---
Hello and welcome to the course on parallel computing in R! My name is Hana Sevcikova and I am a senior research scientist at the University of Washington.
In this course, I assume that you are familiar with the concepts covered in the Writing Efficient R code course here on DataCamp and that you already optimized your sequential code, you know how to benchmark it and you are ready to break it into multiple pieces that can run in parallel, load-balanced and in a reproducible manner.
We start with showing you different ways of splitting problems into pieces and what different methods and R packages are available for running your code in parallel.
In chapter 2 we will go into more detail of the core package called parallel.
The course concludes by paying attention to an important and non-trivial subject of using random numbers in parallel environment and reproducibility. Also in the last chapter, we will put all the concepts together in form of an example.
How do you split a computation problem into parallel chunks? There are two ways you can approach it:
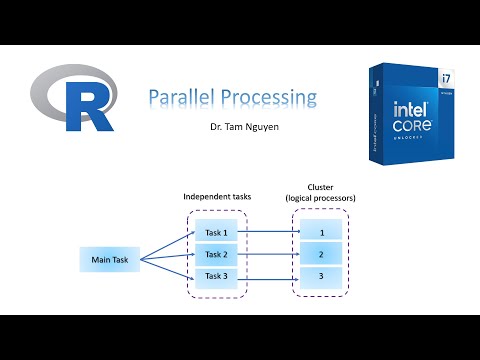
First, you can partition it by tasks where different tasks can be performed independently.
Think of building a house. There are many tasks you can perform in parallel, for example, plumbing, electrical, installing windows etc.
In the modeling world, say a demographic model, births, deaths, and migration can be modeled independently, thus in parallel, providing inputs to a population model.
The second form of partitioning is splitting a computation problem with data. In this case, the same task is performed on different chunks of data.
In the house example, all windows could be installed in parallel.
In computing tasks, you can, for example, compute a sum of each row of a matrix in parallel. You have the same task (which is the sum), applied to different data (which are the rows).
In summary, if you partition a problem by task, it means different tasks are applied to the same or different data.
If you partition by data, the same task is performed on different data. This way of partitioning is much more common and therefore it will be the focus of our course.
Here is another example of partitioning by data. If you have a sequence of operations, say 1 + 2 + 3 + ... + 100,
you can split it into multiple sums where each of the partial sums operates on a subset of the whole sequence and therefore is independent of the others. Thus, the same task, namely the sum, is evaluated on different parts of the data.
If you have a large number of such independent tasks that have low or no communication needs, such applications are often called embarrassingly parallel, meaning, "it’s embarrassing how easy it is to parallelize."
Many statistical simulations belong to this category. They usually have the following structure, here in a pseudo-code:
First, a random number generator is initialized.
Then a loop is constructed in which the same function, here myfunc(), is called usually on different data. Often in such applications, the data is generated as draws from some probability distribution, or it may be simply a subset of a bigger dataset.
After collecting results from each iteration, the results are processed, for example, written to the disk or visualization is created.
Let's look at some real examples.
 0:04:12
0:04:12
 0:03:29
0:03:29
 0:11:34
0:11:34
 0:04:15
0:04:15
 0:11:49
0:11:49
 0:19:25
0:19:25
 0:50:53
0:50:53
 0:16:29
0:16:29
 0:54:26
0:54:26
 0:40:40
0:40:40
 0:17:19
0:17:19
 0:31:38
0:31:38
 1:26:14
1:26:14
 1:58:34
1:58:34
 0:09:04
0:09:04
 0:17:23
0:17:23
 0:09:42
0:09:42
 0:03:13
0:03:13
 0:06:42
0:06:42
 1:02:40
1:02:40
 0:04:47
0:04:47
 0:29:42
0:29:42
 2:02:20
2:02:20
 0:17:30
0:17:30