filmov
tv
Data Lake vs. Delta Lake (aka Data Lakehouse): Which is Right for You?

Показать описание
In today's video, we're diving deep into the world of data storage! Discover the fundamental differences between traditional Data Lakes and the innovative Delta Lake:
🔹 Data Lake: A vast repository storing raw, unstructured data. Great for versatility but can pose challenges in processing and data consistency.
🔹 Delta Lake (Data Lakehouse): An open-source layer designed to address Data Lake's challenges. It offers structured storage, ACID transactions, and unique features like schema evolution and time travel!
Join us as we explore which might be the best fit for your data needs!
#datalake #databricks #datawarehouse #deltalake #datalakehouse
----
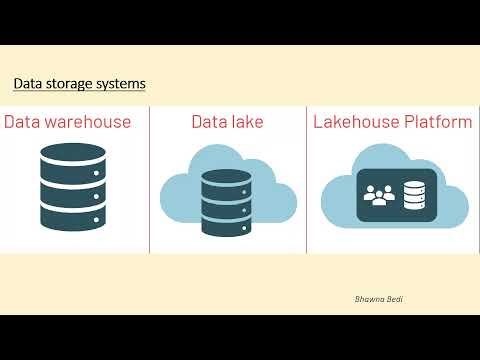
Data Lake
Definition: A data lake is a storage repository, often housed on a distributed data system or cloud platform, that holds a vast amount of raw data in its native format until it's needed. Data lakes can store structured, semi-structured, or unstructured data.
Data Storage: Data lakes typically store data as-is, without imposing a structure or schema. This makes them highly versatile for storing a wide variety of data types.
Data Processing: Due to the lack of immediate structure, data engineers, and data scientists typically have to apply some form of processing (e.g., using Apache Spark, Hive, or other tools) before the data can be used for analytics or machine learning.
Consistency: Traditional data lakes might face issues with data consistency, especially when dealing with concurrent writes and reads, which might lead to data corruption or other problems.
ACID Transactions: Traditional data lakes do not have built-in capabilities to support ACID (Atomicity, Consistency, Isolation, Durability) transactions. This means concurrent data operations might result in conflicts or inconsistencies.
Delta Lake
Definition: Delta Lake is an open-source storage layer that brings ACID transactions to data lakes. It works over your existing data and is fully compatible with API like Spark, Hive, Presto, etc. Databricks, the company behind Delta Lake, introduced it to address many of the shortcomings of traditional data lakes.
Data Storage: Delta Lake stores data in a structured, versioned manner, ensuring that data is reliable and ready for analysis.
Data Processing: While data still requires processing, Delta Lake's approach to maintaining a transaction log ensures that data is consistently ready for reliable querying.
Consistency: One of the primary advantages of Delta Lake is its strong consistency guarantees. The transaction log it maintains records details about every change made to the data, which helps prevent data corruption.
ACID Transactions: Delta Lake supports ACID transactions, enabling multiple concurrent operations without compromising data integrity. This is a significant advantage over traditional data lakes, as it allows for reliable data engineering and analytics operations without the typical headaches of data consistency.
Schema Evolution: Delta Lake supports schema evolution, allowing users to easily change the schema of their tables while maintaining compatibility with their existing data.
Time Travel: Due to its versioned data storage mechanism, Delta Lake provides a "time travel" feature where users can view data as it was at a particular point in time.
In summary, while both data lakes and Delta Lakes aim to store vast amounts of data, the Delta Lake architecture addresses several significant challenges and shortcomings of traditional data lakes by providing features like ACID transactions, schema evolution, and data versioning.
🔹 Data Lake: A vast repository storing raw, unstructured data. Great for versatility but can pose challenges in processing and data consistency.
🔹 Delta Lake (Data Lakehouse): An open-source layer designed to address Data Lake's challenges. It offers structured storage, ACID transactions, and unique features like schema evolution and time travel!
Join us as we explore which might be the best fit for your data needs!
#datalake #databricks #datawarehouse #deltalake #datalakehouse
----
Data Lake
Definition: A data lake is a storage repository, often housed on a distributed data system or cloud platform, that holds a vast amount of raw data in its native format until it's needed. Data lakes can store structured, semi-structured, or unstructured data.
Data Storage: Data lakes typically store data as-is, without imposing a structure or schema. This makes them highly versatile for storing a wide variety of data types.
Data Processing: Due to the lack of immediate structure, data engineers, and data scientists typically have to apply some form of processing (e.g., using Apache Spark, Hive, or other tools) before the data can be used for analytics or machine learning.
Consistency: Traditional data lakes might face issues with data consistency, especially when dealing with concurrent writes and reads, which might lead to data corruption or other problems.
ACID Transactions: Traditional data lakes do not have built-in capabilities to support ACID (Atomicity, Consistency, Isolation, Durability) transactions. This means concurrent data operations might result in conflicts or inconsistencies.
Delta Lake
Definition: Delta Lake is an open-source storage layer that brings ACID transactions to data lakes. It works over your existing data and is fully compatible with API like Spark, Hive, Presto, etc. Databricks, the company behind Delta Lake, introduced it to address many of the shortcomings of traditional data lakes.
Data Storage: Delta Lake stores data in a structured, versioned manner, ensuring that data is reliable and ready for analysis.
Data Processing: While data still requires processing, Delta Lake's approach to maintaining a transaction log ensures that data is consistently ready for reliable querying.
Consistency: One of the primary advantages of Delta Lake is its strong consistency guarantees. The transaction log it maintains records details about every change made to the data, which helps prevent data corruption.
ACID Transactions: Delta Lake supports ACID transactions, enabling multiple concurrent operations without compromising data integrity. This is a significant advantage over traditional data lakes, as it allows for reliable data engineering and analytics operations without the typical headaches of data consistency.
Schema Evolution: Delta Lake supports schema evolution, allowing users to easily change the schema of their tables while maintaining compatibility with their existing data.
Time Travel: Due to its versioned data storage mechanism, Delta Lake provides a "time travel" feature where users can view data as it was at a particular point in time.
In summary, while both data lakes and Delta Lakes aim to store vast amounts of data, the Delta Lake architecture addresses several significant challenges and shortcomings of traditional data lakes by providing features like ACID transactions, schema evolution, and data versioning.
 0:10:23
0:10:23
 0:03:24
0:03:24
 0:06:58
0:06:58
 0:05:22
0:05:22
 0:02:31
0:02:31
 0:09:54
0:09:54
 0:09:32
0:09:32
 0:06:30
0:06:30
 0:08:51
0:08:51
 0:08:10
0:08:10
 0:01:00
0:01:00
 0:58:10
0:58:10
 0:05:46
0:05:46
 0:12:07
0:12:07
 0:22:34
0:22:34
 0:05:12
0:05:12
 0:07:21
0:07:21
 0:08:46
0:08:46
 0:10:14
0:10:14
 0:16:07
0:16:07
 0:14:14
0:14:14
 0:23:52
0:23:52
 0:13:30
0:13:30