filmov
tv
Deploy FULLY PRIVATE & FAST LLM Chatbots! (Local + Production)
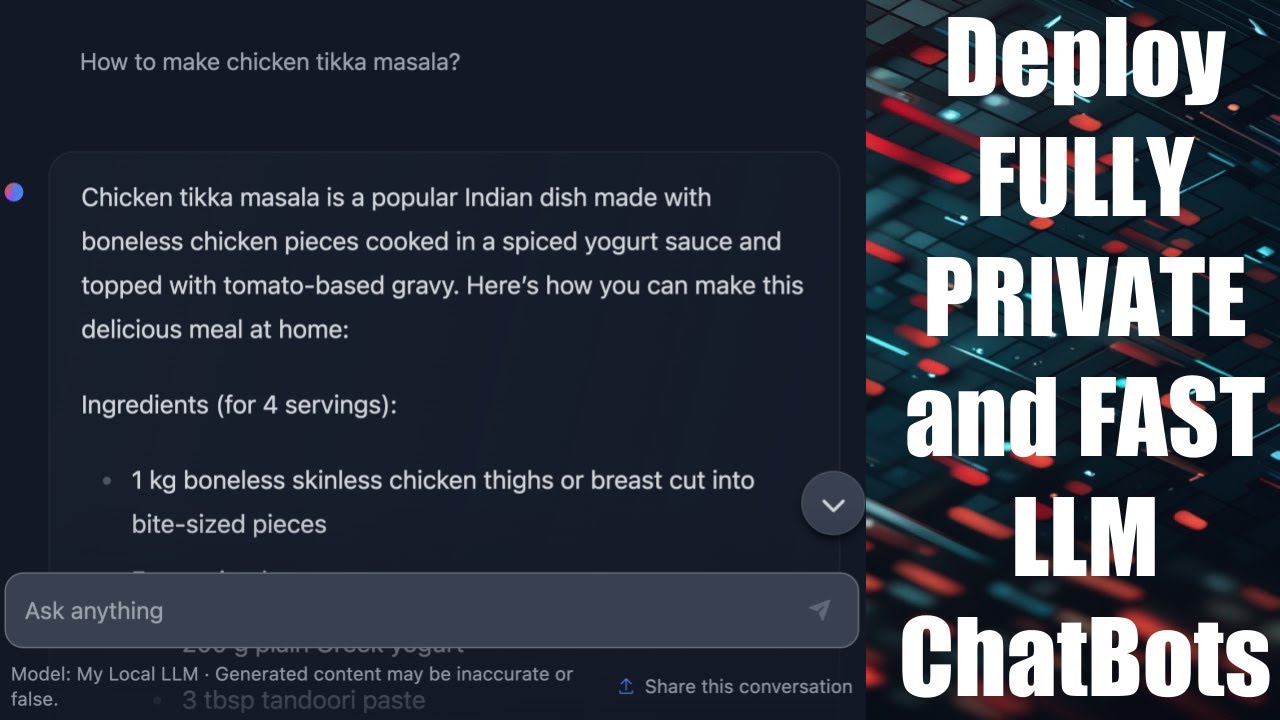
Показать описание
In this video, I'll show you how you can deploy and run large language model (LLM) chatbots locally. The steps followed are also valid for production environment and the tutorial is also production ready! By the end of the tutorial, you will be running an LLM like Falcon-7B (or 40B or any LLM) locally and you would have also deployed a chat interface to use the local llm and chat with it!
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
Follow me on:
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
Follow me on:
 0:19:08
0:19:08
Deploy FULLY PRIVATE & FAST LLM Chatbots! (Local + Production)
 0:02:15
0:02:15
Fastest Way to Deploy a Full Stack Web App (Railway)
 0:00:43
0:00:43
Deploying a Website to AWS in Under 1 Minute
 0:05:55
0:05:55
Why People Aren't Deploying to Vercel Anymore
 0:08:51
0:08:51
HOST a website for FREE using AWS? | Deploy a Website to AWS in Under 8 Minute | AWS + DevOps
 0:06:33
0:06:33
How to Deploy a Node.js App to Render.com for Free (Heroku Alternative)
 0:02:12
0:02:12
Build and Deploy a Machine Learning App in 2 Minutes
 0:04:05
0:04:05
Easily Deploy to Vercel with One Click
 0:19:51
0:19:51
Deploy NodeJS Application on AWS - Amazon Web Services | NodeJS
 0:04:11
0:04:11
FastAPI - Deploy your App in 2 minutes on Deta Space - FASTEST API DEPLOYMENT!
 0:00:20
0:00:20
Deploy a Private Github Repository
 0:10:42
0:10:42
Deploy ML model quickly and easily | Deploying machine learning models quickly and easily
 0:09:31
0:09:31
How To Deploy a NextJS App To Vercel (EASY AND QUICK!!!)
 0:11:52
0:11:52
Fastest Way to Deploy a Database (10 Seconds!?)
 0:20:09
0:20:09
How To Deploy Any Web Application In 15 Minutes Tutorial | VPS + Coolify Combo
 0:40:09
0:40:09
AWS re:Invent 2022 - How to deploy a private mobile network in days using AWS Private 5G (HYB204)
 0:12:32
0:12:32
How to Deploy MERN Application on Vercel? HOST Full-Stack MERN App to Vercel for Free
 0:29:12
0:29:12
Smart contracts, private test chain and deployment to Ethereum with Nethereum
 0:05:08
0:05:08
How To Deploy to Heroku in 5 Minutes
 0:01:39
0:01:39
How to build and deploy an app in Flutter in 60 seconds!
 0:10:40
0:10:40
Kubernetes: How to deploy a Simple Game App into Amazon EKS in 10 minutes
 0:13:50
0:13:50
How to Deploy Flask with Gunicorn and Nginx (on Ubuntu)
 0:18:58
0:18:58
How To Deploy Machine Learning Models Using FastAPI-Deployment Of ML Models As API’s
 0:04:49
0:04:49
Node.js Express Deployment on Vercel: Quick and Easy
Комментарии