filmov
tv
Fast and Efficient AI Inference
Показать описание
Presentation by Song Han, MIT Assistant Professor
NCSAatIllinois
Рекомендации по теме
0:27:12
Fast and Efficient AI Inference
0:10:41
AI Inference: The Secret to AI's Superpowers
0:02:57
The secret to cost-efficient AI inference
0:38:28
Qualcomm: High Performance and Power Efficient AI Inference Acceleration
0:00:57
Fastest Whisper Inference Engine ON THE PLANET!
0:01:30
FPT AI Inference in Action: Easily Integrate LLMs with Model-as-a-Service Platform
0:00:58
Breaking free from the dial-up era of AI inference
0:00:20
Intel's AI Inference Focus vs. Nvidia's CUDA Standard | GenAI News CW50 #aigenerated
0:04:06
Cuttinge Edge AI: Chain of Draft (CoD) #ai #llms #generativeai #promptengineering #chainofdraft
0:16:32
The Hidden Weapon for AI Inference EVERY Engineer Missed
0:03:39
Cerebras vs Nvidia: The AI Chip Revolution 20X Faster Inference, Scalability, and Cost Breakthroughs
0:08:12
“Boost Your AI Inference with OpenVINO 2025 – Complete Install Tutorial”
0:00:15
Tesla's AI Inference Computer The Best in the Market
0:00:58
🤖 'What is Inference in AI? How AI Makes Smart Predictions! | Explanation #AI #AIInference
0:29:32
EdgeCortix: Energy-Efficient, Reconfigurable and Scalable AI Inference Accelerator for Edge Devices
0:05:25
MAX Inference Cluster: AI Inference Reimagined across GPUs
0:16:01
Groq LPUs: Ultra-Fast Inference for AI Workloads | Accelerated Compute Series
0:18:57
Unveiling Nvidia Dynamo: Revolutionizing AI Inference at Scale for Lightning Fast Responses
0:01:01
Cerebras Inference: 68x Faster with Llama3.1-70B!
0:01:21
Boost AI Performance: Why AI Inference Matters & How Baseten Helps
0:05:22
Revolutionary AI Inference Stack Unveiled Today
0:54:58
AI Tech Talk from Plumerai: Demo of the world’s fastest inference engine for Arm Cortex-M
0:05:08
Accelerate LLMs with SampleAttention: Faster Inference, Long Contexts, Zero Accuracy Loss
0:07:35
SysML 18: Jonathan Binas, Analog electronic deep networks for fast and efficient inference
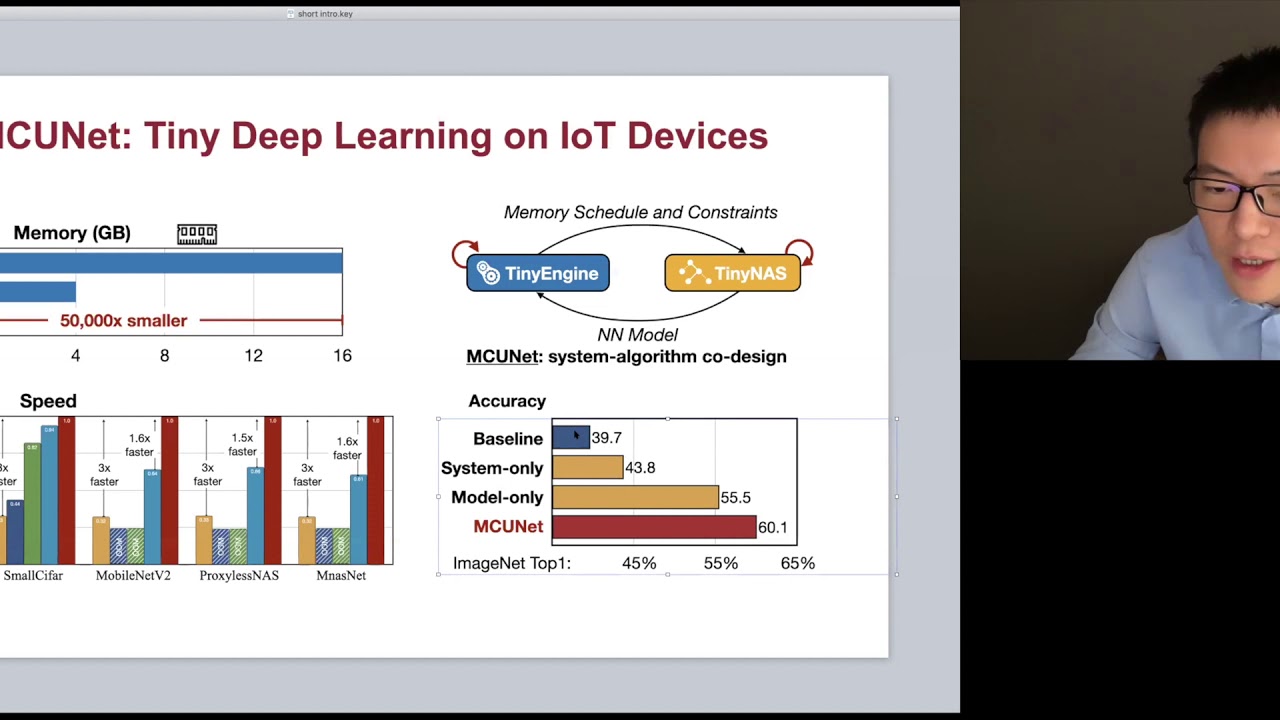
 0:27:12
0:27:12
 0:10:41
0:10:41
 0:02:57
0:02:57
 0:38:28
0:38:28
 0:00:57
0:00:57
 0:01:30
0:01:30
 0:00:58
0:00:58
 0:00:20
0:00:20
 0:04:06
0:04:06
 0:16:32
0:16:32
 0:03:39
0:03:39
 0:08:12
0:08:12
 0:00:15
0:00:15
 0:00:58
0:00:58
 0:29:32
0:29:32
 0:05:25
0:05:25
 0:16:01
0:16:01
 0:18:57
0:18:57
 0:01:01
0:01:01
 0:01:21
0:01:21
 0:05:22
0:05:22
 0:54:58
0:54:58
 0:05:08
0:05:08
 0:07:35
0:07:35