filmov
tv
Lesson 18: Deep Learning Foundations to Stable Diffusion
Показать описание
We continue by implementing the OneCycleLR scheduler from PyTorch, which adjusts the learning rate and momentum during training. We also discuss how to improve the architecture of a neural network by making it deeper and wider, introducing ResNets and the concept of residual connections. Finally, we explore various ResNet architectures from the PyTorch Image Models (timm) library and experiment with data augmentation techniques, such as random erasing and test time augmentation.
0:00:00 - Accelerated SGD done in Excel
0:01:35 - Basic SGD
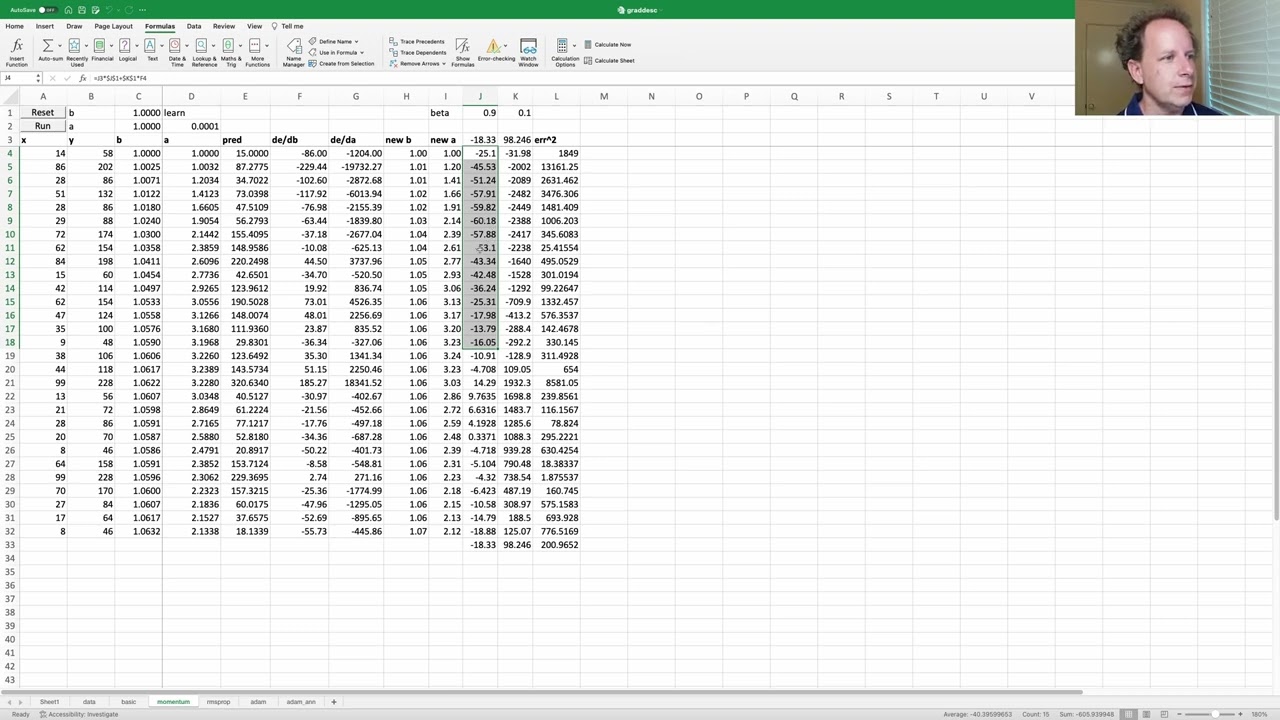
0:10:56 - Momentum
0:15:37 - RMSProp
0:16:35 - Adam
0:20:11 - Adam with annealing tab
0:23:02 - Learning Rate Annealing in PyTorch
0:26:34 - How PyTorch’s Optimizers work?
0:32:44 - How schedulers work?
0:34:32 - Plotting learning rates from a scheduler
0:36:36 - Creating a scheduler callback
0:40:03 - Training with Cosine Annealing
0:42:18 - 1-Cycle learning rate
0:48:26 - HasLearnCB - passing learn as parameter
0:51:01 - Changes from last week, /compare in GitHub
0:52:40 - fastcore’s patch to the Learner with lr_find
0:55:11 - New fit() parameters
0:56:38 - ResNets
1:17:44 - Training the ResNet
1:21:17 - ResNets from timm
1:23:48 - Going wider
1:26:02 - Pooling
1:31:15 - Reducing the number of parameters and megaFLOPS
1:35:34 - Training for longer
1:38:06 - Data Augmentation
1:45:56 - Test Time Augmentation
1:49:22 - Random Erasing
1:55:55 - Random Copying
1:58:52 - Ensembling
2:00:54 - Wrap-up and homework
Many thanks to Francisco Mussari for timestamps and transcription.
 2:05:57
2:05:57
Lesson 18: Deep Learning Foundations to Stable Diffusion
 1:45:42
1:45:42
Lesson 20: Deep Learning Foundations to Stable Diffusion
 1:56:33
1:56:33
Lesson 17: Deep Learning Foundations to Stable Diffusion
 1:30:03
1:30:03
Lesson 19: Deep Learning Foundations to Stable Diffusion
 1:49:37
1:49:37
Lesson 14: Deep Learning Foundations to Stable Diffusion
 1:40:56
1:40:56
Lesson 23: Deep Learning Foundations to Stable Diffusion
 1:46:01
1:46:01
Lesson 13: Deep Learning Foundations to Stable Diffusion
 1:25:39
1:25:39
Lesson 16: Deep Learning Foundations to Stable Diffusion
 0:42:56
0:42:56
Deep Learning chapter 2 : Training Deep Neural Networks | Machine Learning full course in Hindi
 2:15:16
2:15:16
Lesson 9: Deep Learning Foundations to Stable Diffusion
 1:55:47
1:55:47
Lesson 21: Deep Learning Foundations to Stable Diffusion
 1:55:48
1:55:48
Lesson 24: Deep Learning Foundations to Stable Diffusion
 1:37:18
1:37:18
Lesson 15: Deep Learning Foundations to Stable Diffusion
 0:11:07
0:11:07
Need of Batch Normalization || Lesson 18 || Deep Learning || Learning Monkey ||
 1:48:17
1:48:17
Lesson 11 2022: Deep Learning Foundations to Stable Diffusion
 1:49:14
1:49:14
Lesson 10: Deep Learning Foundations to Stable Diffusion, 2022
 0:14:10
0:14:10
Foundation Engineering ( Chapter 18 Introduction to Deep Foundations Part 1 )
 1:50:24
1:50:24
Lesson 12: Deep Learning Foundations to Stable Diffusion
 0:04:59
0:04:59
Quantum Computing In 5 Minutes | Quantum Computing Explained | Quantum Computer | Simplilearn
 0:06:58
0:06:58
Foundation Engineering ( Chapter 18 Introduction to Deep Foundations Part 2 )
 1:03:52
1:03:52
Chapter 18 Fundamentals of Metal forming
 0:08:42
0:08:42
What is the most important influence on child development | Tom Weisner | TEDxUCLA
 3:26:17
3:26:17
Deep Learning Basics Tutorial | Deep Learning Fundamentals | Deep Learning Training | Simplilearn
 0:42:30
0:42:30
Network Physical Layer, Part 1
Комментарии