filmov
tv
Reinforcement Learning from Human Feedback (RLHF) & Direct Preference Optimization (DPO) Explained

Показать описание
Learn how Reinforcement Learning from Human Feedback (RLHF) actually works and why Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO) are changing the game.
This video doesn't go deep on math. Instead, I provide a high-level overview of each technique to help you make practical decisions about where to focus your time and energy.
0:52 The Idea of Reinforcement Learning
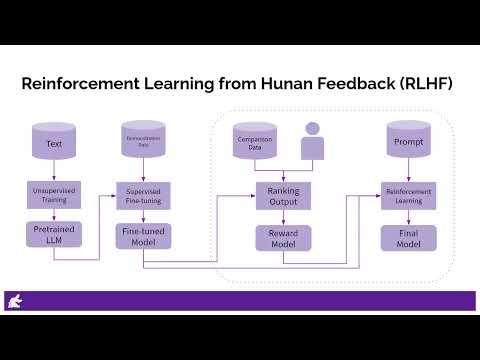
1:55 Reinforcement Learning from Human Feedback (RLHF)
4:21 RLHF in a Nutshell
5:06 RLHF Variations
6:11 Challenges with RLHF
7:02 Direct Preference Optimization (DPO)
7:47 Preferences Dataset Example
8:29 DPO in a Nutshell
9:25 DPO Advantages over RLHF
10:32 Challenges with DPO
10:50 Kahneman-Tversky Optimization (KTO)
11:39 Prospect Theory
13:35 Sigmoid vs Value Function
13:49 KTO Dataset
15:28 KTO in a Nutshell
15:54 Advantages of KTO
18:03 KTO Hyperparameters
These are the three papers referenced in the video:
The Huggingface TRL library offers implementations for PPO, DPO, and KTO:
Want to prototype with prompts and supervised fine-tuning? Try Entry Point AI:
How about connecting? I'm on LinkedIn:
This video doesn't go deep on math. Instead, I provide a high-level overview of each technique to help you make practical decisions about where to focus your time and energy.
0:52 The Idea of Reinforcement Learning
1:55 Reinforcement Learning from Human Feedback (RLHF)
4:21 RLHF in a Nutshell
5:06 RLHF Variations
6:11 Challenges with RLHF
7:02 Direct Preference Optimization (DPO)
7:47 Preferences Dataset Example
8:29 DPO in a Nutshell
9:25 DPO Advantages over RLHF
10:32 Challenges with DPO
10:50 Kahneman-Tversky Optimization (KTO)
11:39 Prospect Theory
13:35 Sigmoid vs Value Function
13:49 KTO Dataset
15:28 KTO in a Nutshell
15:54 Advantages of KTO
18:03 KTO Hyperparameters
These are the three papers referenced in the video:
The Huggingface TRL library offers implementations for PPO, DPO, and KTO:
Want to prototype with prompts and supervised fine-tuning? Try Entry Point AI:
How about connecting? I'm on LinkedIn:
 0:11:29
0:11:29
Reinforcement Learning from Human Feedback (RLHF) Explained
 0:10:17
0:10:17
Reinforcement Learning through Human Feedback - EXPLAINED! | RLHF
 1:00:38
1:00:38
Reinforcement Learning from Human Feedback: From Zero to chatGPT
 0:03:27
0:03:27
New course with Google Cloud: Reinforcement Learning from Human Feedback (RLHF)
 0:10:48
0:10:48
RLHF+CHATGPT: What you must know
 2:15:13
2:15:13
Reinforcement Learning from Human Feedback explained with math derivations and the PyTorch code.
 0:15:31
0:15:31
Reinforcement Learning with Human Feedback - How to train and fine-tune Transformer Models
 0:59:17
0:59:17
RLHF: How to Learn from Human Feedback with Reinforcement Learning
 0:51:28
0:51:28
TESOL in A Global Perspective: A Lesson Learned
 0:08:13
0:08:13
Reinforcement Learning from Human Feedback (Natural Language Processing at UT Austin)
 0:09:08
0:09:08
Reinforcement Learning from Human Feedback Explained (and RLAIF)
 0:06:31
0:06:31
Reinforcement Learning: ChatGPT and RLHF
 0:55:41
0:55:41
Lessons from reinforcement learning from human feedback | Stephen Casper | EAG Boston 23
 0:04:59
0:04:59
Reinforcement Learning from Human Feedback (RLHF) Explained
 1:15:46
1:15:46
CMU Advanced NLP Fall 2024 (8): Reinforcement Learning and Human Feedback
 0:01:00
0:01:00
The Magic of Reinforcement Learning with Human Feedback RLHF
 1:03:32
1:03:32
John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
 0:12:38
0:12:38
Reinforcement Learning from Human Feedback (RLHF)
 0:19:39
0:19:39
Reinforcement Learning from Human Feedback (RLHF) & Direct Preference Optimization (DPO) Explain...
 0:17:24
0:17:24
15min History of Reinforcement Learning and Human Feedback
 0:05:54
0:05:54
RLAIF vs. RLHF: the technology behind Anthropic’s Claude (Constitutional AI Explained)
 1:11:49
1:11:49
RLHF - Reinforcement Learning with Human Feedback
 0:13:38
0:13:38
How RLHF Makes Apps More Intuitive (Reinforcement Learning from Human Feedback)
 0:56:30
0:56:30
RLHF - Reinforcement Learning from Human Feedback
Комментарии