filmov
tv
Reinforcement Learning through Human Feedback - EXPLAINED! | RLHF

Показать описание
We talk about reinforcement learning through human feedback. ChatGPT among other applications makes use of this.
ABOUT ME
PLAYLISTS FROM MY CHANNEL
MATH COURSES (7 day free trial)
OTHER RELATED COURSES (7 day free trial)
ABOUT ME
PLAYLISTS FROM MY CHANNEL
MATH COURSES (7 day free trial)
OTHER RELATED COURSES (7 day free trial)
 0:11:29
0:11:29
Reinforcement Learning from Human Feedback (RLHF) Explained
 0:10:17
0:10:17
Reinforcement Learning through Human Feedback - EXPLAINED! | RLHF
 0:09:08
0:09:08
Reinforcement Learning from Human Feedback Explained (and RLAIF)
 0:00:52
0:00:52
What is Reinforcement Learning through Human Feedback (RLHF)?
 0:15:31
0:15:31
Reinforcement Learning with Human Feedback - How to train and fine-tune Transformer Models
 1:00:38
1:00:38
Reinforcement Learning from Human Feedback: From Zero to chatGPT
 0:01:00
0:01:00
The Magic of Reinforcement Learning with Human Feedback RLHF
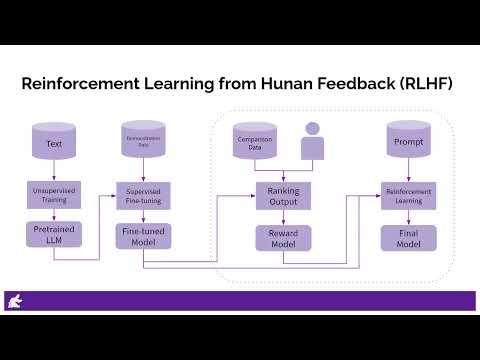 0:04:59
0:04:59
Reinforcement Learning from Human Feedback (RLHF) Explained
 2:15:13
2:15:13
Reinforcement Learning from Human Feedback explained with math derivations and the PyTorch code.
 0:10:48
0:10:48
RLHF+CHATGPT: What you must know
 0:56:30
0:56:30
RLHF - Reinforcement Learning from Human Feedback
 0:54:29
0:54:29
CS 285: Eric Mitchell: Reinforcement Learning from Human Feedback: Algorithms & Applications
 0:17:24
0:17:24
15min History of Reinforcement Learning and Human Feedback
 0:06:31
0:06:31
Reinforcement Learning: ChatGPT and RLHF
 0:03:27
0:03:27
New course with Google Cloud: Reinforcement Learning from Human Feedback (RLHF)
 0:08:13
0:08:13
Reinforcement Learning from Human Feedback (Natural Language Processing at UT Austin)
 1:03:32
1:03:32
John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
 0:01:29
0:01:29
Reinforcement Learning Explained: Correcting models with feedback
 0:00:31
0:00:31
What is RLHF (or reinforcement learning from human feedback)
 0:06:25
0:06:25
Reinforcement Learning from Human Feedback (RLHF) - Beginners Guide | AI Foundation Learning
 0:24:11
0:24:11
Learning Task Specifications for Reinforcement Learning from Human Feedback | David Lindner
 0:59:17
0:59:17
RLHF: How to Learn from Human Feedback with Reinforcement Learning
 0:12:38
0:12:38
Reinforcement Learning from Human Feedback (RLHF)
 1:10:21
1:10:21
AI TeaTalk Singapore #1: Learn from Human Feedback with Reinforcement Learning - Natasha Jaques
Комментарии