filmov
tv
Solving one of PostgreSQL's biggest weaknesses.

Показать описание
Storing large amounts of data, such as time series data, in a single table is often a challenge when it comes to PostgreSQL. There are other databases out there that can be used for timeseries, however, it does mean giving up many of the features that makes postgres so desirable.
Fortunately, there is another option. TimeScaleDB is a postgres extension that is optimized for time series data. In this video, we provide a brief introduction into TimeScale DB and put it to the test.
This video was sponsored by TimeScaleDB. If you're looking to use a time series database for your own needs, then I highly recommend TimeScale, you can get set up with a free trial using the link below.
Join this channel to get access to perks:
My socials:
My Equipment:
Video Links:
00:00 - Intro
00:56 - Timeseries Data
02:40 - Getting Started
07:33 - HyperTables
12:38 - Continuous Aggregates
16:39 - Results
Fortunately, there is another option. TimeScaleDB is a postgres extension that is optimized for time series data. In this video, we provide a brief introduction into TimeScale DB and put it to the test.
This video was sponsored by TimeScaleDB. If you're looking to use a time series database for your own needs, then I highly recommend TimeScale, you can get set up with a free trial using the link below.
Join this channel to get access to perks:
My socials:
My Equipment:
Video Links:
00:00 - Intro
00:56 - Timeseries Data
02:40 - Getting Started
07:33 - HyperTables
12:38 - Continuous Aggregates
16:39 - Results
 0:17:12
0:17:12
Solving one of PostgreSQL's biggest weaknesses.
 0:08:12
0:08:12
5 Secrets for making PostgreSQL run BLAZING FAST. How to improve database performance.
 0:00:24
0:00:24
Coding for 1 Month Versus 1 Year #shorts #coding
 0:49:11
0:49:11
Future(s) of PostgreSQL (Multi-Master) Replication
 0:05:57
0:05:57
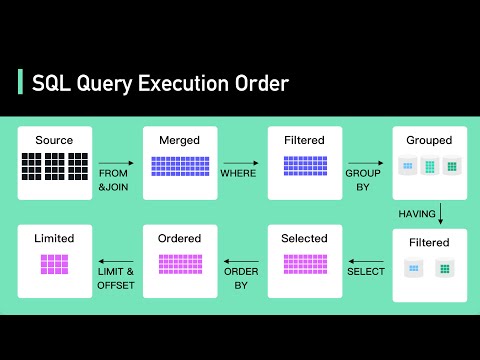
Secret To Optimizing SQL Queries - Understand The SQL Execution Order
 0:00:25
0:00:25
Most ideal approach to Solve PostgreSQL Copy Syntax Error through PostgreSQL Remote Database Service
 0:31:21
0:31:21
PostgreSQL Indexing : How, why, and when.
 0:06:00
0:06:00
Advanced Aggregate Functions in SQL (GROUP BY, HAVING vs. WHERE)
 0:00:16
0:00:16
YS Jagan Davos Trolls #ysjagan #appolitics ycp trolls YCPLatestTrolls Latest Shorts
 0:09:51
0:09:51
SQL Server Tutorial - One-to-many and many-to-many table relationships
 0:21:54
0:21:54
What I learned interviewing the PostgreSQL Community | Citus Con: An Event for Postgres 2022
 0:33:11
0:33:11
Mostly mistaken and ignored parameters while optimizing a #PostgreSQL #database - #Percona Live 2020
 0:30:45
0:30:45
PostgreSQL, performance for queries with grouping
 0:49:11
0:49:11
Langote & Bapat: Partition and conquer large data with PostgreSQL 10 - PGCon 2017
 0:04:05
0:04:05
HOW TO JOIN 3 OR MORE TABLES IN SQL | TWO WAYS
 0:02:37
0:02:37
Supabase in 100 Seconds
 0:02:27
0:02:27
MongoDB in 100 Seconds
 0:12:54
0:12:54
Lec-70: Find Nth(1st,2nd,3rd....N) Highest Salary in SQL | Imp for Competitive & Placement exam
 0:00:48
0:00:48
Ab India seekhega Coding ❤️
 0:00:30
0:00:30
Junior Developer v/s Senior Developer😛 #shorts #funny
 0:01:00
0:01:00
Find The Length Size Of Array PostgreSQL pgAdmin SQL Query #postgresql
 0:22:32
0:22:32
PostgreSQL as a Big Data Platform by Chris Travers
 0:43:01
0:43:01
PostgreSQL + ZFS: Best Practices and Standard Procedures
 0:08:37
0:08:37
Advanced SQL Tutorial | Subqueries
Комментарии