filmov
tv
Reinforcement Learning From Human Feedback, RLHF. Overview of the Process. Strengths and Weaknesses.

Показать описание
Dive into the captivating world of Reinforcement Learning with Human Feedback (RLfH), one of the most sophisticated topics in fine-tuning large language models. This comprehensive guide offers an overview of crucial concepts, focusing on powerful techniques like Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO).
We begin with an exploration of reinforcement learning's overarching goal: alignment. Uncover the importance of developing models that are not just accurate but also well-behaved and user-friendly, and learn how this approach aids in curbing misleading or inappropriate responses.
Moving forward, we delve into key concepts integral to RLfH such as state and observation space, action space, policy space, trajectories, and reward functions. Discover how derivatives play a pivotal role in calculating gradients and updates for our weights, and grasp the significance of the Hessian matrix in gauging loss sensitivity.
As we unpack RLfH, we unravel the complexities of the PPO and TRPO algorithms. Learn how these techniques aim to modify the network's parameters to achieve desirable behavior, thereby ensuring the alignment of the model's responses with user expectations. We provide an easy-to-follow walkthrough of these algorithms, explaining the significance of their objective functions and their treatment of the KL Divergence, a measure of the difference between two probability distributions.
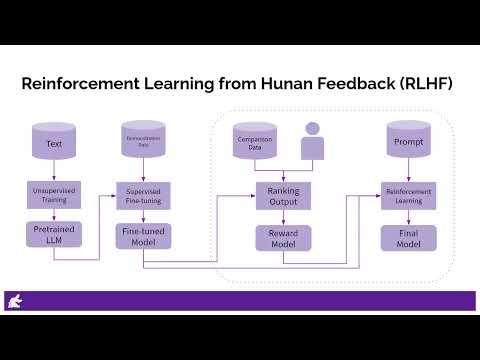
Then, we guide you through the implementation of these principles into an RLfH pipeline, highlighting the key steps: initial training, collection of human feedback, and the iterative process of reinforcement learning. Understand the tangible benefits of this approach, such as enhanced performance, adaptability, continuous improvement, and safety, as well as the challenges it poses, namely scalability and subjectivity.
Wrapping up, we introduce an exemplary PPO implementation using a library. Experiment, play, and learn in this interactive Google Collab, seeing firsthand the impact of different hyperparameters and data set changes.
This video offers an enlightening journey into the intricacies of RLfH, designed to give you a solid grasp of these complex concepts. Whether you're a professional or just intrigued by the potential of reinforcement learning, you're sure to find value here. Stay tuned for more content on large language models, fine-tuning validations, and much more! Please like, subscribe, and let us know what you'd like to learn next in the comments. Happy learning!
0:00 Intro
0:36 Key Concepts
2:45 Reinforcement Depth
6:54 TRPO and PPO
14:20 RLHF Process
17:15 PPO Library
181:6 Outro
#ReinforcementLearning, #HumanFeedback, #LargeLanguageModels, #MachineLearning, #PPO, #TRPO
We begin with an exploration of reinforcement learning's overarching goal: alignment. Uncover the importance of developing models that are not just accurate but also well-behaved and user-friendly, and learn how this approach aids in curbing misleading or inappropriate responses.
Moving forward, we delve into key concepts integral to RLfH such as state and observation space, action space, policy space, trajectories, and reward functions. Discover how derivatives play a pivotal role in calculating gradients and updates for our weights, and grasp the significance of the Hessian matrix in gauging loss sensitivity.
As we unpack RLfH, we unravel the complexities of the PPO and TRPO algorithms. Learn how these techniques aim to modify the network's parameters to achieve desirable behavior, thereby ensuring the alignment of the model's responses with user expectations. We provide an easy-to-follow walkthrough of these algorithms, explaining the significance of their objective functions and their treatment of the KL Divergence, a measure of the difference between two probability distributions.
Then, we guide you through the implementation of these principles into an RLfH pipeline, highlighting the key steps: initial training, collection of human feedback, and the iterative process of reinforcement learning. Understand the tangible benefits of this approach, such as enhanced performance, adaptability, continuous improvement, and safety, as well as the challenges it poses, namely scalability and subjectivity.
Wrapping up, we introduce an exemplary PPO implementation using a library. Experiment, play, and learn in this interactive Google Collab, seeing firsthand the impact of different hyperparameters and data set changes.
This video offers an enlightening journey into the intricacies of RLfH, designed to give you a solid grasp of these complex concepts. Whether you're a professional or just intrigued by the potential of reinforcement learning, you're sure to find value here. Stay tuned for more content on large language models, fine-tuning validations, and much more! Please like, subscribe, and let us know what you'd like to learn next in the comments. Happy learning!
0:00 Intro
0:36 Key Concepts
2:45 Reinforcement Depth
6:54 TRPO and PPO
14:20 RLHF Process
17:15 PPO Library
181:6 Outro
#ReinforcementLearning, #HumanFeedback, #LargeLanguageModels, #MachineLearning, #PPO, #TRPO
 0:11:29
0:11:29
Reinforcement Learning from Human Feedback (RLHF) Explained
 0:10:17
0:10:17
Reinforcement Learning through Human Feedback - EXPLAINED! | RLHF
 1:00:38
1:00:38
Reinforcement Learning from Human Feedback: From Zero to chatGPT
 0:03:27
0:03:27
New course with Google Cloud: Reinforcement Learning from Human Feedback (RLHF)
 0:10:48
0:10:48
RLHF+CHATGPT: What you must know
 2:15:13
2:15:13
Reinforcement Learning from Human Feedback explained with math derivations and the PyTorch code.
 0:15:31
0:15:31
Reinforcement Learning with Human Feedback - How to train and fine-tune Transformer Models
 0:08:13
0:08:13
Reinforcement Learning from Human Feedback (Natural Language Processing at UT Austin)
 0:05:54
0:05:54
NVIDIA's Llama-3.1-Nemotron-70B-Instruct: Revolutionizing AI Alignment with HelpSTEER2
 0:59:17
0:59:17
RLHF: How to Learn from Human Feedback with Reinforcement Learning
 0:09:08
0:09:08
Reinforcement Learning from Human Feedback Explained (and RLAIF)
 0:04:59
0:04:59
Reinforcement Learning from Human Feedback (RLHF) Explained
 0:01:00
0:01:00
The Magic of Reinforcement Learning with Human Feedback RLHF
 0:55:41
0:55:41
Lessons from reinforcement learning from human feedback | Stephen Casper | EAG Boston 23
 0:06:31
0:06:31
Reinforcement Learning: ChatGPT and RLHF
 0:17:24
0:17:24
15min History of Reinforcement Learning and Human Feedback
 0:12:38
0:12:38
Reinforcement Learning from Human Feedback (RLHF)
 0:32:02
0:32:02
ByteDance's Platform for Reinforcement Learning from Human Feedback | Ray Summit 2024
 0:19:39
0:19:39
Reinforcement Learning from Human Feedback (RLHF) & Direct Preference Optimization (DPO) Explain...
 1:03:32
1:03:32
John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
 0:05:54
0:05:54
RLAIF vs. RLHF: the technology behind Anthropic’s Claude (Constitutional AI Explained)
 0:13:38
0:13:38
How RLHF Makes Apps More Intuitive (Reinforcement Learning from Human Feedback)
 1:00:38
1:00:38
Reinforcement Learning from Human Feedback From Zero to ChatGPT [Record of the live]
 0:00:40
0:00:40
Reinforcement Learning from Human Feedback
Комментарии