filmov
tv
8.3 Bias-Variance Decomposition of the Squared Error (L08: Model Evaluation Part 1)
Показать описание
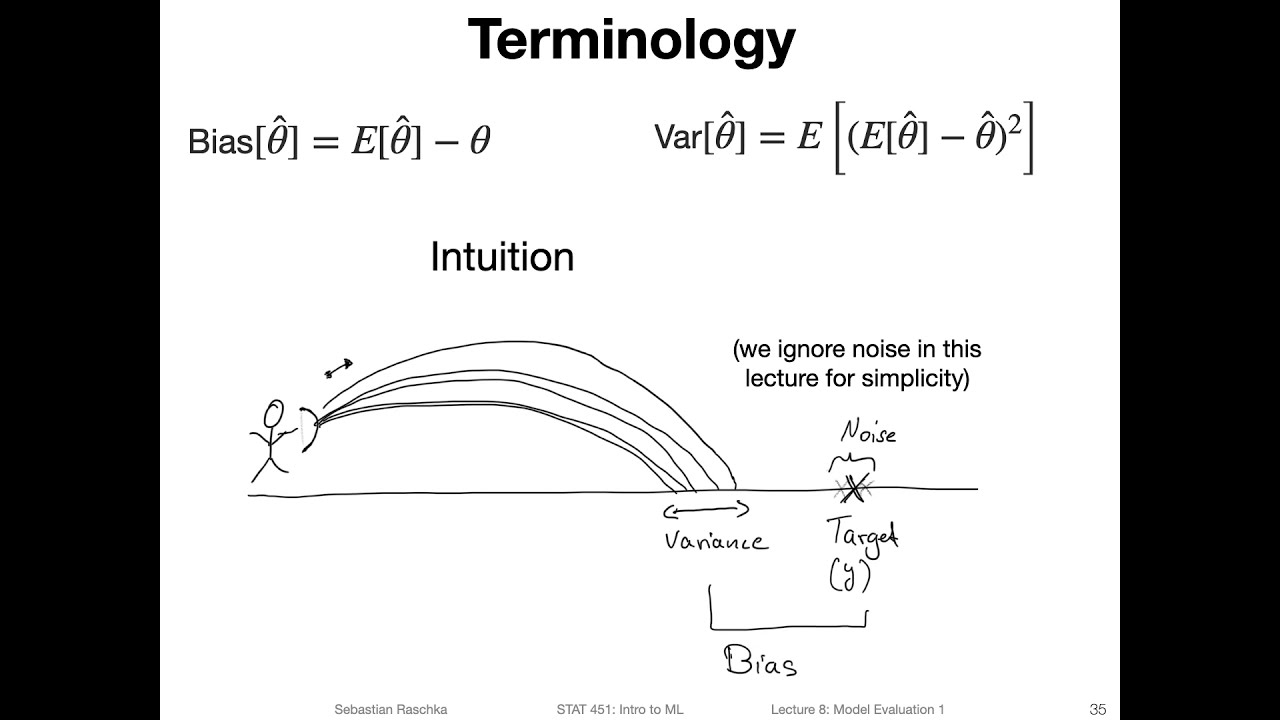
In this video, we decompose the squared error loss into its bias and variance components.
-------
This video is part of my Introduction of Machine Learning course.
-------
-------
This video is part of my Introduction of Machine Learning course.
-------
 0:06:36
0:06:36
Machine Learning Fundamentals: Bias and Variance
 0:08:20
0:08:20
DTEL2 2 3 Bias variance Decomposition
 0:23:22
0:23:22
8.5 Bias-Variance Decomposition of the 0/1 Loss (L08: Model Evaluation Part 1)
 0:42:21
0:42:21
Machine Learning 29: Bias-Variance Decomposition
 0:08:01
0:08:01
Overfitting in ML: Bias-Variance Decomposition
 0:04:57
0:04:57
Bias and Variance, Simplified
 0:03:50
0:03:50
3.2 Bias and Variance, Bias Variance Trade off
 0:08:38
0:08:38
Machine Learning: Bias VS Variance
 0:15:24
0:15:24
The Bias Variance Trade-Off
 0:07:15
0:07:15
Bias and Variance for Machine Learning | Deep Learning
 0:08:06
0:08:06
Learning To See [Part 9: Bias Variance Throwdown]
 0:10:50
0:10:50
Machine Learning Tutorial Python - 20: Bias vs Variance In Machine Learning
 0:08:47
0:08:47
Bias Variance Trade off | with Salary Prediction Example | bias variance decomposition | ML
 0:08:47
0:08:47
Bias/Variance (C2W1L02)
 0:51:37
0:51:37
Lec 3: Bias-Variance Tradeoff
 0:09:05
0:09:05
MH4510 Lecture 3 part 5 - bias-variance trade-off for cross validation
 2:03:02
2:03:02
Assignments 1 & 2 Solutions, Bias-Variance Decomposition (Week 3 - Live)
 0:11:17
0:11:17
KNN Regression and the Bias-Variance Tradeoff
 0:05:05
0:05:05
Bias-Variance Tradeoff
 0:18:23
0:18:23
Lecture 11 - Part 3 - Bias Variance with Noise
 0:06:38
0:06:38
Bias-Variance Tradeoff
 0:08:18
0:08:18
19. Variance Decomposition in Rstudio
 0:08:05
0:08:05
Bias Variance Trade-off | Overfitting and Underfitting in Machine Learning
 0:00:20
0:00:20
1st yr. Vs Final yr. MBBS student 🔥🤯#shorts #neet
Комментарии