filmov
tv
My first choice model with PandasBiogeme 3.2.6

Показать описание
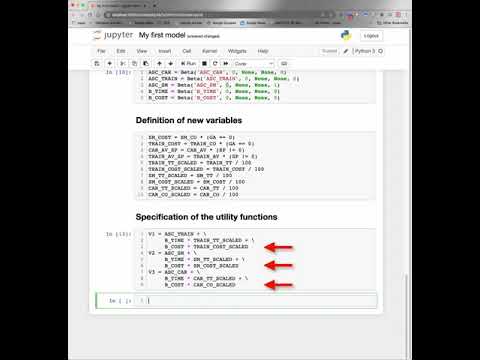
The video walks you through the specification and estimation of a simple choice model with the Python package PandasBiogeme
 0:16:17
0:16:17
My first choice model with Pandasbiogeme
 0:19:26
0:19:26
My first choice model with PandasBiogeme 3.2.6
 0:19:26
0:19:26
My first choice model with PandasBiogeme 3.2.6
 0:02:01
0:02:01
How To Register for myFirstChoice
 0:35:47
0:35:47
Building The Perfect $7,000 Collection For Every Scenario (4 Options)
 0:00:48
0:00:48
Trump: Airplane Accuser 'Would Not Be My First Choice'
 0:20:15
0:20:15
Our Top-5 compact SUVs for 2025 // Which would you choose and why?
 0:02:12
0:02:12
Getting to Know myFirstChoice
 0:06:51
0:06:51
You NEED This In 2024!?… | Moza R5 Bundle review 2024
 0:03:16
0:03:16
'My First Choice' an Alex Thao original
 0:00:30
0:00:30
First Choice ‘That’s Why We’re Your First Choice’ TVC via Bashful
 0:00:16
0:00:16
First Choice IPS🔥🤔💯 #vikash_divyakirti_sir #vikash_sir ❤ #IPS_Motivation #IAS #UPSC #viral🔥💯...
 0:00:16
0:00:16
Always my #firstchoice
 0:01:00
0:01:00
My girlfriend admitted I was Not her First Choice Physically when we started Dating
 0:00:11
0:00:11
Avengers Will Always Be My First Choice
 0:00:48
0:00:48
Trump on accuser: She would not be my first choice
 0:00:28
0:00:28
One Fine Day With First Choice #shorts
 0:00:09
0:00:09
“You will always be my first choice”#milklove #short #panlyloverruuk
 0:00:10
0:00:10
Not my first choice but it checks out #designerbag
 0:01:07
0:01:07
Raina - CF is my First Choice
 0:00:33
0:00:33
My first choice | #youtubeshorts #beautystation#sparklediaries
 0:00:10
0:00:10
Natasha ❤️ My First Choice 💞So Cute 💕 #natasha #dhawal #shorts
 0:01:26
0:01:26
McPherson Carbon Series - Always My First Choice
 0:01:10
0:01:10
My First Choice for Home Mortgage
Комментарии