filmov
tv
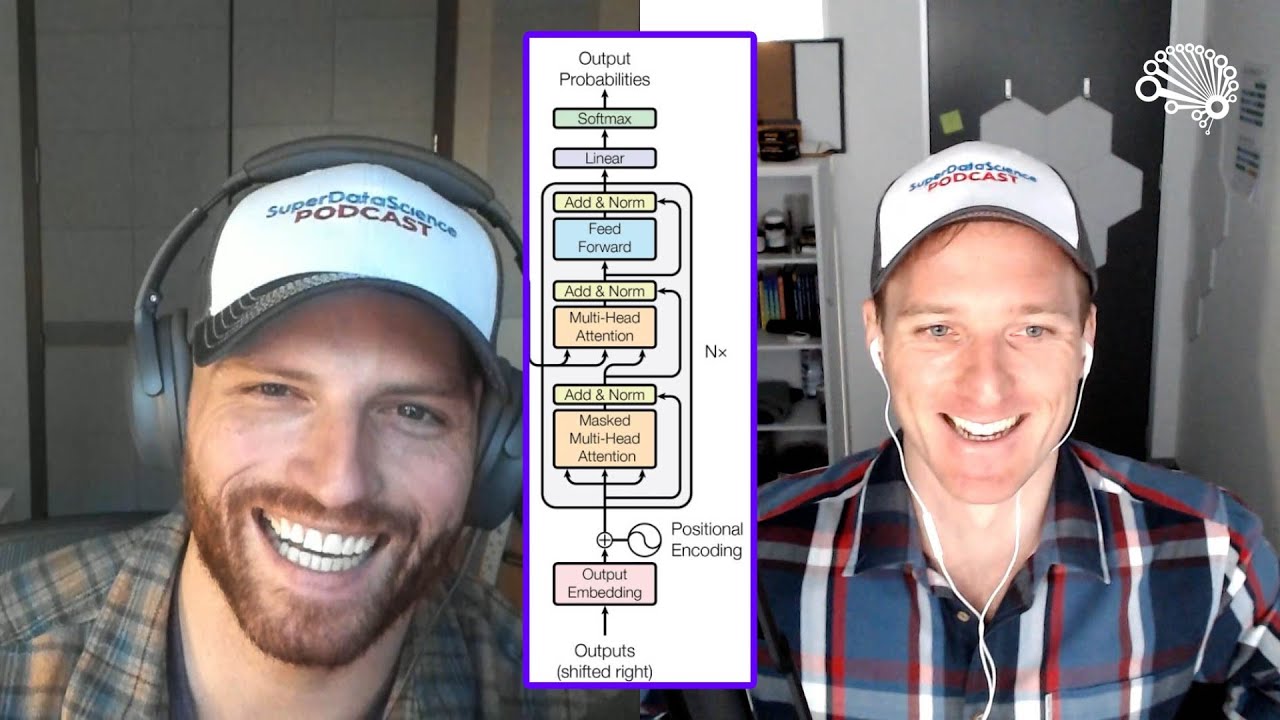
How Decoder-Only Transformers (like GPT) Work
Показать описание
Learn about encoders, cross attention and masking for LLMs as SuperDataScience Founder Kirill Eremenko returns to the SuperDataScience podcast, to speak with @JonKrohnLearns about transformer architectures and why they are a new frontier for generative AI. If you’re interested in applying LLMs to your business portfolio, you’ll want to pay close attention to this episode!
 0:36:45
0:36:45
Decoder-Only Transformers, ChatGPTs specific Transformer, Clearly Explained!!!
 0:18:56
0:18:56
How Decoder-Only Transformers (like GPT) Work
 0:07:38
0:07:38
Which transformer architecture is best? Encoder-only vs Encoder-decoder vs Decoder-only models
 0:04:27
0:04:27
Transformer models: Decoders
 0:03:48
0:03:48
MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers
 0:18:52
0:18:52
Encoder-Only Transformers (like BERT) for RAG, Clearly Explained!!!
 0:00:58
0:00:58
LLM Transformers Encoder Only vs Decoder Only vs Encoder Decoder Models
 0:15:30
0:15:30
Confused which Transformer Architecture to use? BERT, GPT-3, T5, Chat GPT? Encoder Decoder Explained
 0:02:58
0:02:58
BERT and GPT in Language Models like ChatGPT or BLOOM | EASY Tutorial on Large Language Models LLM
 0:31:11
0:31:11
Coding a ChatGPT Like Transformer From Scratch in PyTorch
 0:15:01
0:15:01
Illustrated Guide to Transformers Neural Network: A step by step explanation
 0:06:49
0:06:49
Transformer Explainer- Learn About Transformer With Visualization
 0:06:47
0:06:47
Transformer models: Encoder-Decoders
 1:56:20
1:56:20
Let's build GPT: from scratch, in code, spelled out.
 0:04:09
0:04:09
Tutorial 14: Encoder only and Decoder only Transformers in HINDI | BERT, BART, GPT
 0:36:15
0:36:15
Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!!
 0:08:45
0:08:45
Encoder-Decoder Transformers vs Decoder-Only vs Encoder-Only: Pros and Cons
 0:00:49
0:00:49
Decoder architecture in 60 seconds
 0:04:46
0:04:46
Transformer models: Encoders
 0:00:56
0:00:56
GPT vs T5 #NLP #AI #MachineLearning #T5 #GPT
 0:00:45
0:00:45
Why masked Self Attention in the Decoder but not the Encoder in Transformer Neural Network?
 0:00:59
0:00:59
Decoder training with transformers
 0:26:10
0:26:10
Attention in transformers, step-by-step | Deep Learning Chapter 6
 0:02:58
0:02:58
Introduction to LLMs: Encoder Vs Decoder Models
Комментарии