filmov
tv
State and Action Values in a Grid World: A Policy for a Reinforcement Learning Agent

Показать описание
** Apologies for the low volume. Just turn it up **
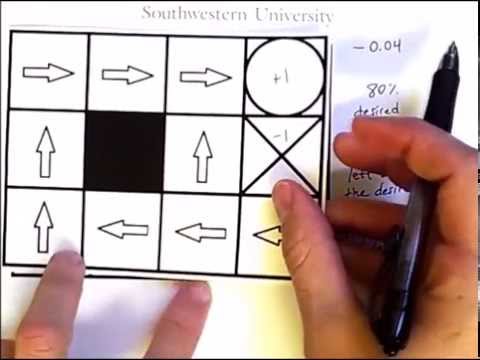
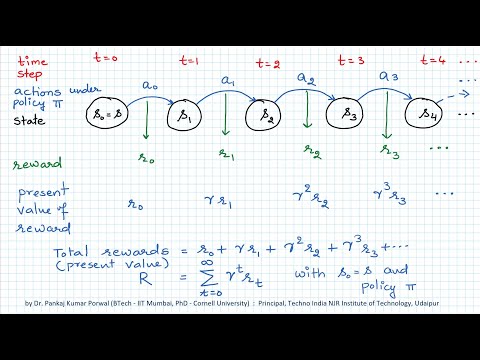
This video uses a grid world example to set up the idea of an agent following a policy and receiving rewards in a sequential decision making task, also known as a Reinforcement Learning problem. Although there is no learning agent yet in this video, the concepts of state values (utility) and Q-values are discussed, which are vital components of many RL algorithms. The grid world formulation comes from the book Artificial Intelligence: A Modern Approach, by Russell and Norvig.
This video uses a grid world example to set up the idea of an agent following a policy and receiving rewards in a sequential decision making task, also known as a Reinforcement Learning problem. Although there is no learning agent yet in this video, the concepts of state values (utility) and Q-values are discussed, which are vital components of many RL algorithms. The grid world formulation comes from the book Artificial Intelligence: A Modern Approach, by Russell and Norvig.
 0:13:53
0:13:53
State and Action Values in a Grid World: A Policy for a Reinforcement Learning Agent
 0:08:25
0:08:25
19. State Value & Action Value Function || End to End AI Tutorial
 0:07:51
0:07:51
State Value (V) and Action Value ( Q Value ) Derivation - Reinforcement Learning - Machine Learning
 0:01:12
0:01:12
Reinforcement learning: State values vs and action values qs, a
 0:50:34
0:50:34
MDP-2 | State value | Action value | Reinforcement Learning (INF8953DE) | Lecture - 3 | Part - 1
 1:01:30
1:01:30
TTMS5. Q-Learning: Learning the Optimal State-Action Value
 0:10:04
0:10:04
Inaccuracy of State-Action Value Function for Non-Optimal Actions in Adversarially...: Ezgi Korkmaz
 0:04:12
0:04:12
What is State Value Function & Action Value Function in Tamil || Reinforcement Learning
 0:00:06
0:00:06
5 DARK PSYCHOLOGY TIPS #psychology #motivation #english #quotes
 2:14:37
2:14:37
L08: Reinforcement Learning I - Policies, State Action Value Functions
 0:09:46
0:09:46
21. Action Value Function || End to End AI Tutorial
 0:00:16
0:00:16
Action-Value Learning
 0:01:50
0:01:50
Steve Kerr: Core Values In Action
 0:15:53
0:15:53
Values in tech. Just buzzwords or action items? | PlatformCon 2023
 0:00:21
0:00:21
Developing Trust: Moving From a Value to an Action
 0:01:23
0:01:23
Old National - Our Values in Action
 0:00:33
0:00:33
What Is VIA (Values In Action) Survey? Discovering Your Character Strengths!
 0:01:04
0:01:04
Army Values in Action
 0:16:34
0:16:34
RL#20 Bellman Equation Part 2 Action Value function and further | The RL Series
 1:59:30
1:59:30
Deep Learning (Spring 2022) L10: Reinforcement Learning I: Policies, State-Action Value Functions
 0:07:06
0:07:06
L2: Bellman Equation (P5-Action value)—Mathematical Foundations of RL
 0:00:16
0:00:16
Putting Our Values Into Action
 0:56:55
0:56:55
From Values to Action: The Four Principles of Values-Based Leadership
 0:07:04
0:07:04
From Values to Action | Values Based Organizing
Комментарии