filmov
tv
Algorithms: Graph Search, DFS and BFS

Показать описание
 0:11:49
0:11:49
Algorithms: Graph Search, DFS and BFS
 0:18:31
0:18:31
5.1 Graph Traversals - BFS & DFS -Breadth First Search and Depth First Search
 0:04:01
0:04:01
Depth-first search in 4 minutes
 0:10:30
0:10:30
Graph Search Algorithms in 100 Seconds - And Beyond with JS
 0:10:20
0:10:20
Depth First Search Algorithm | Graph Theory
 0:15:22
0:15:22
Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms
 0:13:01
0:13:01
Top 5 Most Common Graph Algorithms for Coding Interviews
 0:20:52
0:20:52
Depth First Search (DFS) Explained: Algorithm, Examples, and Code
 0:04:00
0:04:00
Depth-First Search (DFS) Explained: GATE CS Preparation | Graph Traversal Algorithm
 0:07:41
0:07:41
Learn Depth First Search in 7 minutes ⬇️
 0:03:59
0:03:59
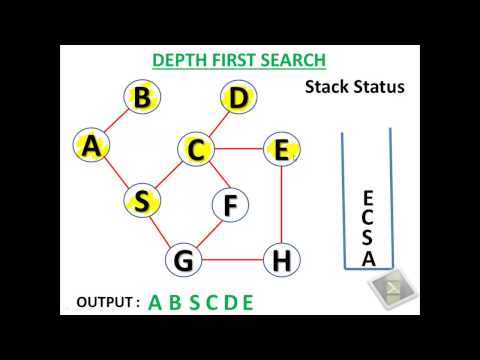
Breadth-first search in 4 minutes
 0:03:47
0:03:47
Depth First Search Algorithm
 2:12:19
2:12:19
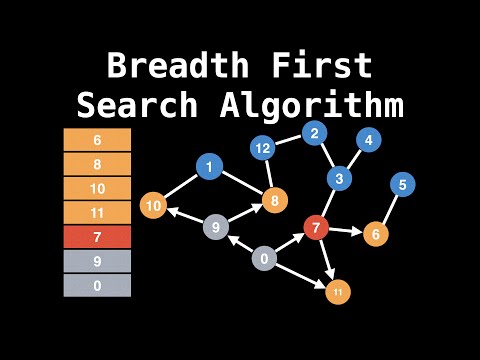
Graph Algorithms for Technical Interviews - Full Course
 0:07:23
0:07:23
Breadth First Search Algorithm | Shortest Path | Graph Theory
 0:20:27
0:20:27
6.2 BFS and DFS Graph Traversals| Breadth First Search and Depth First Search | Data structures
 0:06:46
0:06:46
Graph Searching 5 Performing DFS by Hand
 0:07:16
0:07:16
Depth First Search
 0:00:34
0:00:34
Depth First Search (DFS) Algorithm Explained
 0:00:05
0:00:05
Breadth and depth first search
 0:19:12
0:19:12
Graph Search Visualization in Python (BFS and DFS)
 0:04:39
0:04:39
Graph Searching 7 Example of Edge Classification
 0:01:56
0:01:56
Graph Traversals - Depth First Search (DFS) Animated
 0:01:39
0:01:39
Animation of Graph DFS(depth first search) Algorithm set to music
 0:06:25
0:06:25
Graphs - Depth First Search
Комментарии