filmov
tv
How To Get Answers From Your PDF Using Azure OpenAI And Langchain

Показать описание
Check out this video to learn about querying your PDF file using Azure OpenAI and Langchain.
** REFERRAL LINK *************
** REFERRAL LINK *************
###### MORE PLAYLISTS ######
#openai #chatbot #chatgpt
** REFERRAL LINK *************
** REFERRAL LINK *************
###### MORE PLAYLISTS ######
#openai #chatbot #chatgpt
 0:00:52
0:00:52
How To See All The Answers in Google Form (UPDATED 2024)
 0:02:28
0:02:28
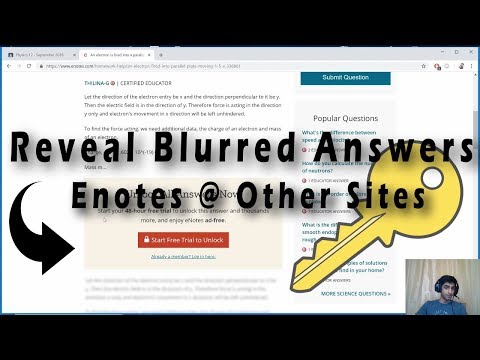
Life Hack: Reveal Blurred Answers [Math, Physics, Science, English]
 0:01:46
0:01:46
How to See All Answers in Google Forms 2024
 0:02:23
0:02:23
How to find answer on Google Fast MCQs Answers on Google MSBTE Exam Cheating
 0:01:15
0:01:15
How to get Google Forms Answers.Get Google Forms Answers in seconds.#onlinetest#google#hacks#tricks
 0:28:21
0:28:21
HOW To Crack and find ANSWERS to Questions in ONLINE EXAMS OR APTITUDE TESTS | Beat The System
 0:04:47
0:04:47
How To Get Answers To Your Prayers
 0:04:15
0:04:15
How To Upload Images To ChatGPT And Get Answers!
 0:02:33
0:02:33
Parents of SLPS students still struggling to get answers from district on transportation
 0:06:10
0:06:10
How to ace a test without knowing the answers: Multiple Choice Test Hacks!
 0:00:20
0:00:20
Get answers from Google with Google Nest Mini
 0:08:39
0:08:39
IELTS Speaking Band 9 Clear and Confident Answers (2023)
 0:06:01
0:06:01
How Do You Get To Know Yourself Fully? - Sadhguru answers at Entreprenuers Organization Meet
 8:00:01
8:00:01
Life-Changing 8 Hr. Sleep #Hypnosis: Get Clarity, Truth, & Answers From Deep, Untapped Higher Se...
 0:07:27
0:07:27
How to Get Answers for Any Homework or Test
 0:12:08
0:12:08
Questions No One Knows the Answers to (Full Version)
 0:00:30
0:00:30
How to get A+ in Math exams
 0:14:18
0:14:18
Toxicologist Answers Poison Questions From Twitter | Tech Support | WIRED
 0:00:16
0:00:16
How to get answers on Google Forms
 0:13:26
0:13:26
IELTS Reading for Band 9 without Skim and Scan for Answers
 0:19:54
0:19:54
🧾Microsoft Forms - Get All Answers 🤯
 0:05:27
0:05:27
Get the Answers
 0:04:14
0:04:14
Job interview in English | Job interview questions and answers | Learn English | Sunshine English
 0:00:31
0:00:31
Wrong answers only, what is this? 🤮🤮🤮 #thatlittlepuff #ChefPuff #catsofyoutube
Комментарии