filmov
tv
Generating Unique Identifiers in Your Programs (GUIDs/UUIDs)

Показать описание
---
Generating Unique Identifiers in Your Programs (GUIDs/UUIDs) // Globally- or Universally-Unique Identifiers are a common tool for assigning unique handles to devices, objects, and database entries. This video takes you through the different types of GUID/UUID and shows you how to generate them, both from your C programs and the command line.
***
Welcome! I post videos that help you learn to program and become a more confident software developer. I cover beginner-to-advanced systems topics ranging from network programming, threads, processes, operating systems, embedded systems and others. My goal is to help you get under-the-hood and better understand how computers work and how you can use them to become stronger students and more capable professional developers.
About me: I'm a computer scientist, electrical engineer, researcher, and teacher. I specialize in embedded systems, mobile computing, sensor networks, and the Internet of Things. I teach systems and networking courses at Clemson University, where I also lead the PERSIST research lab.
More about me and what I do:
To Support the Channel:
+ like, subscribe, spread the word
Generating Unique Identifiers in Your Programs (GUIDs/UUIDs) // Globally- or Universally-Unique Identifiers are a common tool for assigning unique handles to devices, objects, and database entries. This video takes you through the different types of GUID/UUID and shows you how to generate them, both from your C programs and the command line.
***
Welcome! I post videos that help you learn to program and become a more confident software developer. I cover beginner-to-advanced systems topics ranging from network programming, threads, processes, operating systems, embedded systems and others. My goal is to help you get under-the-hood and better understand how computers work and how you can use them to become stronger students and more capable professional developers.
About me: I'm a computer scientist, electrical engineer, researcher, and teacher. I specialize in embedded systems, mobile computing, sensor networks, and the Internet of Things. I teach systems and networking courses at Clemson University, where I also lead the PERSIST research lab.
More about me and what I do:
To Support the Channel:
+ like, subscribe, spread the word
 0:21:36
0:21:36
Generating Unique Identifiers in Your Programs (GUIDs/UUIDs)
 0:05:56
0:05:56
Generate Unique ID for your record | Basics of PowerApps | Power Platform for Beginners | Now()
 0:00:47
0:00:47
A quick UUID generator (universal unique identifier)
 0:06:15
0:06:15
How to Create Unique ID for SharePoint List Records Using Power Automate - Automatic ID Generator
 0:06:25
0:06:25
Excel: Streamline Your Workflow: Auto-Generate an ID Number When New Row is Populated
 0:06:36
0:06:36
Generate A Unique ID In Power Apps
 0:08:17
0:08:17
How to Use Excel IF Function to Generate ID Number | Dynamic Excel Serial and ID number: No VBA
 0:00:48
0:00:48
Unique Id Generator in JavaScript
 0:00:33
0:00:33
Skyfair ka ID kaise create kare
 0:03:22
0:03:22
Excel create a unique identifier for a VLookup
 0:04:24
0:04:24
Google Form and Google Sheet Auto generate unique ID
 0:00:30
0:00:30
SQL | Simple unique Id generator
 0:06:38
0:06:38
How to Generate Unique ID for Microsoft Lists Records Using Power Automate
 0:15:04
0:15:04
Generating Unique IDs in Python
 0:02:04
0:02:04
Create a Random ID for your Bubble.io Data
 0:01:11
0:01:11
Flutter Tutorial - Unique Identifier Generator [2022] UUID Package
 0:06:19
0:06:19
How to generate Unique Device Identifiers in Javascript
 0:06:45
0:06:45
Power Apps - Creating Unique Autonumber ID for Records ( Dataverse) - Not GUID #11
 0:06:28
0:06:28
HOW TO GENERATE UNIQUE USER ID USING PHP | MYSQL (EEM_15846_1,EEM_35984_2)
 0:01:00
0:01:00
Generate unique id in JavaScript (using UUID Package)
 0:08:17
0:08:17
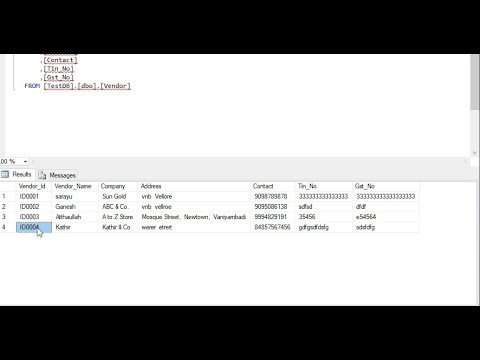
How Generate Custom ID in SQL
 0:04:56
0:04:56
How to Generate Unique ID for Each Device in Javascript
 0:08:30
0:08:30
Create your own unique identifier/ data key in Excel 🔑 (* VLOOKUP *)
 0:08:45
0:08:45
HOW TO GENERATE UNIQUE ID(CHARACTER + NUMBER) FOR CUSTOMER IN SQL SERVER
Комментарии