filmov
tv
monocular 3D bounding box model combined with YOLOv8 for semantic segmentation results

Показать описание
baseline performance level between the best CNN architecture..
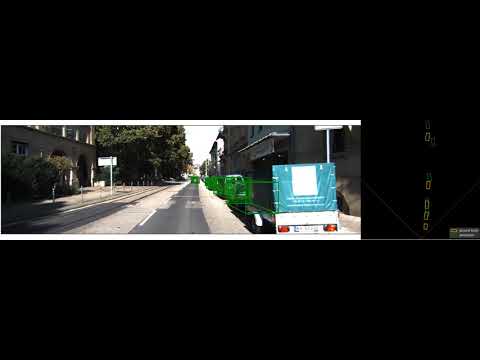
a powerful combination of a Monocular 3D Bounding Box Model and YOLOv8 Semantic Segmentation base models without any Fine-tuning and optimization strategies. This fusion brings depth-aware object detection together with lightning-fast semantic understanding. for incredible advancements in scene comprehension and object localization. #AI #ComputerVision #ObjectDetection #SemanticSegmentation"
Integrated 3D Bounding Box Detection and Depth Estimation for Object Localization
#2D
#3D
#yolov5
#yolov8
#tracking
#efficientnet
#resnet
#mobilenet
#efficientnet
#vgg
#BEV
#tensorflow
#pytorch
#ultralytics
#opencv
#segmentations
simple and easy #YOLOv5 Object Detection with Bird's Eye View and Tracking//
a powerful combination of a Monocular 3D Bounding Box Model and YOLOv8 Semantic Segmentation base models without any Fine-tuning and optimization strategies. This fusion brings depth-aware object detection together with lightning-fast semantic understanding. for incredible advancements in scene comprehension and object localization. #AI #ComputerVision #ObjectDetection #SemanticSegmentation"
Integrated 3D Bounding Box Detection and Depth Estimation for Object Localization
#2D
#3D
#yolov5
#yolov8
#tracking
#efficientnet
#resnet
#mobilenet
#efficientnet
#vgg
#BEV
#tensorflow
#pytorch
#ultralytics
#opencv
#segmentations
simple and easy #YOLOv5 Object Detection with Bird's Eye View and Tracking//
 0:00:54
0:00:54
 0:02:53
0:02:53
 0:01:01
0:01:01
 0:05:06
0:05:06
 0:00:21
0:00:21
 0:01:28
0:01:28
 0:12:46
0:12:46
 0:04:59
0:04:59
 0:02:19
0:02:19
 0:00:16
0:00:16
 0:00:28
0:00:28
 0:03:45
0:03:45
 0:00:16
0:00:16
 0:01:21
0:01:21
 0:01:02
0:01:02
 0:00:52
0:00:52
 0:00:06
0:00:06
 0:00:13
0:00:13
 0:00:16
0:00:16
 0:00:18
0:00:18
 0:04:48
0:04:48
 0:09:21
0:09:21
 0:01:44
0:01:44
 0:00:43
0:00:43