filmov
tv
How to work with Apache Kafka and Hadoop - Gwen Shapira from Cloudera

Показать описание
Getting data from Kafka to Hadoop should be simple, which is why the community has so many options to choose from. Cloudera engineer, Gwen Shapira, reviews some popular solutions: Storm, Spark, Flume and Camus. She goes over the pros and cons of each, and recommends use-cases and future development plans as well.
This talk was given at the Apache Kafka NYC meetup at Tapad.
ABOUT DATA COUNCIL:
FOLLOW DATA COUNCIL:
 0:07:53
0:07:53
Apache vs NGINX
 0:02:08
0:02:08
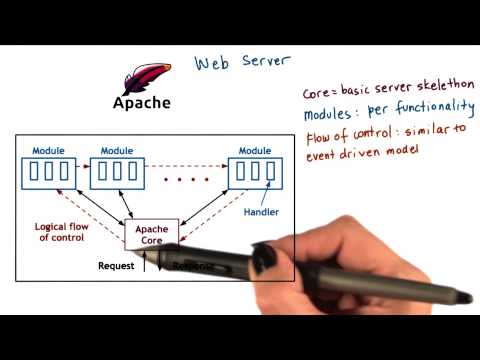
Apache Web Server
 0:20:45
0:20:45
Apache Basics Tutorial | How To Install and Configure Apache2
 0:05:22
0:05:22
Install & Set Up Apache Web Server on Windows 10 - Quickly!
 0:09:46
0:09:46
Apache Helicopter How it Works? Boeing AH-64 Apache
 0:02:06
0:02:06
Apache Web Server - What is...
 0:03:20
0:03:20
Apache Spark in 100 Seconds
 0:02:39
0:02:39
What Is Apache Spark?
 0:01:10
0:01:10
Getting Started with Java in Apache NetBeans
 0:15:59
0:15:59
What is Apache & Nginx? | Apache vs Nginx 🔥🔥
 0:11:38
0:11:38
What is Apache Pinot? (and User-Facing Analytics) | A StarTree Lightboard by Tim Berglund
 0:16:28
0:16:28
Apache Web Server Setup on Ubuntu 22.04 (with SSL)
 0:32:43
0:32:43
Basics of Apache Webserver
 0:12:38
0:12:38
Learn Apache Airflow in 10 Minutes | High-Paying Skills for Data Engineers
 0:17:01
0:17:01
Mastering Apache Tomcat : A Comprehensive Guide For Webserver Setup
 0:06:48
0:06:48
Apache Kafka in 6 minutes
 0:10:11
0:10:11
Linux Apache Web Server HTTPD | Setup with Example in Hindi | Beginners
 0:33:54
0:33:54
Apache Tomcat Server Tutorial for Beginners
 0:11:13
0:11:13
Setup Apache Server as forward proxy, reverse proxy & load balancer. Step by step implementation
 0:10:11
0:10:11
How to Host Websites with Apache Server? | Apache Tutorial for Beginners
 0:04:37
0:04:37
What exactly is Apache Spark? | Big Data Tools
 0:00:53
0:00:53
Apache Airflow in under 60 seconds
 0:02:16
0:02:16
What is Apache?
 0:24:14
0:24:14
3. Apache Kafka Fundamentals | Apache Kafka Fundamentals
Комментарии