filmov
tv
Creating a Non-Clustered Index on Multiple Columns in SQL Server

Показать описание
Explore the impact of creating a non-clustered index on multiple columns in SQL Server for improved database performance.
---
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
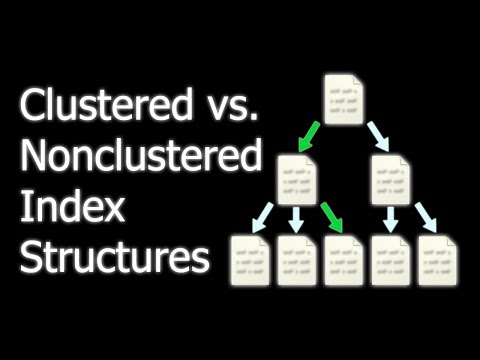
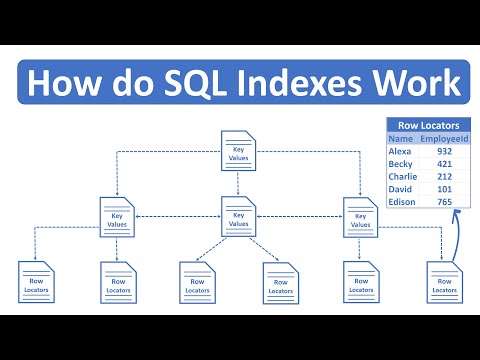
In the world of databases, particularly with Microsoft SQL Server, indexing is a critical method for optimizing the performance of data retrieval operations. One type of indexing available in SQL Server is the Non-Clustered Index. Unlike the clustered index, which sorts and stores the data rows in the table based on their key values, a non-clustered index creates a separate structure within the database that references the data rows.
Can You Create a Non-Clustered Index on Multiple Columns?
Absolutely, SQL Server allows you to create a non-clustered index on multiple columns. This is particularly useful when you need to retrieve data efficiently based on queries that filter on more than one column. For instance, if you often find yourself querying a table based on combinations of columns like LastName and FirstName, a multi-column non-clustered index could enhance the performance of those queries.
How to Create a Non-Clustered Index on Multiple Columns
To create a multi-column non-clustered index in SQL Server 2005, you would typically use the following syntax:
[[See Video to Reveal this Text or Code Snippet]]
This command will add a non-clustered index on Column1, Column2, Column3, and so forth, depending on your table structure and needs.
Effects and Considerations
Query Performance: The most significant advantage of using a non-clustered index on multiple columns is the boost in read performance for queries that filter using those columns. It aligns well with operations such as SELECT, WHERE, and ORDER BY.
Storage Overhead: Non-clustered indexes require additional storage because they create a separate index structure. This storage overhead can be larger when multiple columns are indexed together.
Maintenance Overhead: Updating, inserting, or deleting rows in a table with non-clustered indexes requires additional work. The database must also update the indexed data, leading to potentially increased latency in data write operations.
Index Fragmentation: Multi-column indexes can become fragmented over time, which might degrade performance. Regular maintenance such as reorganizing or rebuilding indexes can help manage this issue effectively.
Selectivity: When creating a multi-column index, the order of the columns matters. Columns should be ordered by their selectivity; place the most selective columns first to improve the index's effectiveness.
Concluding Thoughts
While a non-clustered index on multiple columns can be an excellent tool for optimizing SQL Server performance, it should be used judiciously. Considering factors such as the frequency of read versus write operations, the size of the table, and the selectivity of the combined columns will help you make informed decisions about index creation.
Proper index design in SQL Server, especially with multi-column indexes, is an art that balances performance with resource usage, and it is essential for maintaining efficient and responsive databases.
---
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
In the world of databases, particularly with Microsoft SQL Server, indexing is a critical method for optimizing the performance of data retrieval operations. One type of indexing available in SQL Server is the Non-Clustered Index. Unlike the clustered index, which sorts and stores the data rows in the table based on their key values, a non-clustered index creates a separate structure within the database that references the data rows.
Can You Create a Non-Clustered Index on Multiple Columns?
Absolutely, SQL Server allows you to create a non-clustered index on multiple columns. This is particularly useful when you need to retrieve data efficiently based on queries that filter on more than one column. For instance, if you often find yourself querying a table based on combinations of columns like LastName and FirstName, a multi-column non-clustered index could enhance the performance of those queries.
How to Create a Non-Clustered Index on Multiple Columns
To create a multi-column non-clustered index in SQL Server 2005, you would typically use the following syntax:
[[See Video to Reveal this Text or Code Snippet]]
This command will add a non-clustered index on Column1, Column2, Column3, and so forth, depending on your table structure and needs.
Effects and Considerations
Query Performance: The most significant advantage of using a non-clustered index on multiple columns is the boost in read performance for queries that filter using those columns. It aligns well with operations such as SELECT, WHERE, and ORDER BY.
Storage Overhead: Non-clustered indexes require additional storage because they create a separate index structure. This storage overhead can be larger when multiple columns are indexed together.
Maintenance Overhead: Updating, inserting, or deleting rows in a table with non-clustered indexes requires additional work. The database must also update the indexed data, leading to potentially increased latency in data write operations.
Index Fragmentation: Multi-column indexes can become fragmented over time, which might degrade performance. Regular maintenance such as reorganizing or rebuilding indexes can help manage this issue effectively.
Selectivity: When creating a multi-column index, the order of the columns matters. Columns should be ordered by their selectivity; place the most selective columns first to improve the index's effectiveness.
Concluding Thoughts
While a non-clustered index on multiple columns can be an excellent tool for optimizing SQL Server performance, it should be used judiciously. Considering factors such as the frequency of read versus write operations, the size of the table, and the selectivity of the combined columns will help you make informed decisions about index creation.
Proper index design in SQL Server, especially with multi-column indexes, is an art that balances performance with resource usage, and it is essential for maintaining efficient and responsive databases.
Clustered vs. Nonclustered Index Structures in SQL Server

SQL indexing best practices | How to make your database FASTER!

SQL Server - Creating Non-Clustered Index using SQL Server Management Studio

How to Increase Database Performance | How to create non clustered index in sql server

Creating a Non-Clustered Index

Master Non-Clustered Index Creation in SQL Server Using SSMS: Boost Query Performance!
How do SQL Indexes Work

Creating a Non-Clustered Index on Multiple Columns in SQL Server

How to create Clustered and Non-Clustered index in a table?

How sql indexes work- Nonclustered and Clustered

What is Non-Clustered index ? How to create Non-Clustered index in a table?

how to create non-clustered index in sql server management studio

Create Index in SQL Server, Clustered Index and Non Clustered Index with Example

When to Use Clustered Index and Non-Clustered Index In SQL

SQL Indexes | Clustered vs. Nonclustered Index | #SQL Course 35

Types of SQL Server Indexes: Clustered vs Non-Clustered |SQL Tutorial Day 20

Non Clustered Indexes may hurt modification queries performance (by Amit Bansal)

C# : Create a non-clustered index in Entity Framework Core

SQL Server – Non Clustered Indexes have the Clustering Key (by Amit Bansal)

Most asked SQL interview questions Create a Non clustered Index in SQL Server #sqlserver

02 What is a non clustered index in sql server

How Do Non-Clustered Indexes Improve Performance

Définition and création of a non clustered index | SQL server
