filmov
tv
Standard Error (of the sample mean) | Sampling | Confidence Intervals | Proportions

Показать описание
0:00 Introduction
1:20 Definition
6:40 Confidence Intervals
12:51 Proportions
17:16 Challenge Question
Series music by Purdy.
Song: 3 Friends to the Stars
 0:18:40
0:18:40
Standard Error (of the sample mean) | Sampling | Confidence Intervals | Proportions
 0:46:45
0:46:45
8. Sampling and Standard Error
 0:02:17
0:02:17
What Is a Standard Error?
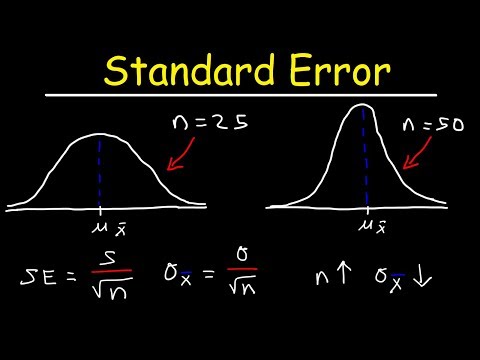 0:10:45
0:10:45
Standard Error of the Mean
 0:07:05
0:07:05
Standard Error
 0:05:01
0:05:01
Understanding Standard Error
 0:07:22
0:07:22
Estimated Standard Error : One Sample
 0:10:21
0:10:21
Standard Deviation Formula, Statistics, Variance, Sample and Population Mean
 0:20:16
0:20:16
MAT 144 Topic 5 prob empirical rule and norm dist
 0:04:07
0:04:07
Simplest Explanation of the Standard Errors of Regression Coefficients - Statistics Help
 0:06:25
0:06:25
Sampling Distribution & Standard Error
 0:03:38
0:03:38
standard error of proportion
 0:03:30
0:03:30
Finding Sample Size, Given Standard Deviation and Standard error of the mean.
 0:11:06
0:11:06
Sampling Distributions (7.2)
 0:02:06
0:02:06
How To Calculate Sample Standard Deviation (Step By Step)
 0:06:24
0:06:24
How to Use Z Score and Standard Error to Determine Sample Probability in Statistics
 0:04:43
0:04:43
Chapter 7 Sample Size and Standard Error
 0:03:09
0:03:09
Standard Error of the Mean in Excel
 0:08:32
0:08:32
04 Effect of Sample Size on Standard Error
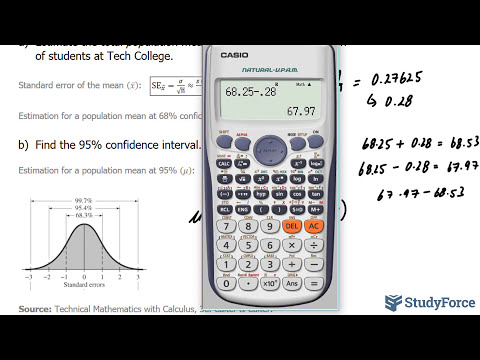 0:05:06
0:05:06
📚 How to find the standard error of a sample mean to estimate the population mean
 0:04:16
0:04:16
Standard Error for the mean of a stratified sample
 0:02:49
0:02:49
What is sampling error?
 0:05:25
0:05:25
Standard Error of the Mean: Concept and Formula | Statistics Tutorial #6 | MarinStatsLectures
 0:09:32
0:09:32
Sample standard deviation and bias | Probability and Statistics | Khan Academy
Комментарии