filmov
tv
OpenCV 3 KNN Character Recognition Python

Показать описание
GitHub site:
Prerequisite:
If you found this video helpful please consider supporting me on Patreon:
Prerequisite:
If you found this video helpful please consider supporting me on Patreon:
 0:10:06
0:10:06
OpenCV 3 KNN Character Recognition C++
 0:07:40
0:07:40
OpenCV 3 KNN Character Recognition Python
 0:22:34
0:22:34
OpenCV 3 KNN Character Recognition Emgu CV 3 Visual Basic
 0:36:24
0:36:24
OpenCV Intro to Character Recognition and Machine Learning with KNN in Visual Basic and C#
 0:34:33
0:34:33
OpenCV Intro to Character Recognition and Machine Learning with KNN
 0:02:58
0:02:58
OpenCV 3 by Example : Introducing Optical Character Recognition | packtpub.com
 0:00:50
0:00:50
Handwriting recognition in Open CV
 0:00:47
0:00:47
Character Recognition using Tesseract and OpenCV
 0:04:14
0:04:14
Hands-On OpenCV 4 with Python: Optical Character Recognition –What, Why, and How?|packtpub.com
 0:05:48
0:05:48
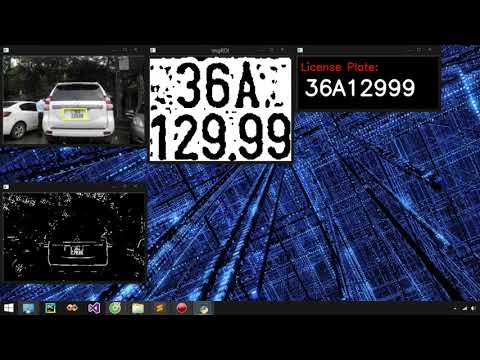
Automatic License Plate Recognition using OpenCV, Python, KNN
 0:00:40
0:00:40
OpenCV Text Detection (EAST text detector) Demo
 0:06:25
0:06:25
Vietnamese license plate recognition in 3 steps using opencv and knn
 0:01:13
0:01:13
Opencv KNN OCR + Darknet Yolo, License plate recognize realtime
 0:08:01
0:08:01
python machine learning OCR system
 0:01:04
0:01:04
Ocr using pytesseract + opencv + pyqt5
 0:27:45
0:27:45
Knn handwritten digits recognition – OpenCV 3.4 with python 3 Tutorial 36
 0:01:49
0:01:49
250 Visualizing the Characters in an Optical Character Recognition Database
 0:00:12
0:00:12
OCR Technology (Optical Character Recognition)
 0:06:57
0:06:57
How to Recognize License Plate with Python OpenCV Machine learning?
 0:02:37
0:02:37
OpenCV Text Recognition
 0:03:47
0:03:47
OCR PROB IN PYTHON
![[kNN] Number Recognition](https://i.ytimg.com/vi/_bbKBqqpKUU/hqdefault.jpg) 0:05:01
0:05:01
[kNN] Number Recognition using OpenCV, Python - Night
 0:07:08
0:07:08
Detecting License Plate and Identifying the Registration Details using OpenCV and Python
 0:02:13
0:02:13
Simple Digit Recognition OCR in OpenCV Python
Комментарии