filmov
tv
Reduce System Complexity with Data Oriented Programming

Показать описание
Title: Reduce System Complexity with Data Oriented Programming
Date: January 25, 2023
Duration: 1HR
ABSTRACT
Complexity is one of the main difficulties in the development of successful software systems. Modern programming languages and frameworks make it easy to develop and deploy our code quickly, but as the code base grows, complexity makes it challenging to add new features.
Data-oriented programming is a paradigm that aims at reducing the complexity of information systems such as back-end applications, web services, web workers, and front-end applications by rethinking data. Data-oriented programming treats data as an immutable value that is manipulated by general-purpose functions. Moreover, data is validated à la carte.
In this talk, we illustrate the principles of data-oriented programming in the context of a software production system. After attending this talk, you will be able to apply data-oriented programming principles in your preferred programming language and reduce the complexity of the systems you build.
Takeaways
1. Apply Data-Oriented Programming principles in your preferred programming language.
2. Apply data validation techniques without using static types.
3. Represent data with immutable data structures.
4. Manipulate data with generic functions.
SPEAKER
Yehonathan Sharvit, Software Architect, Cycognito
Yehonathan Sharvit has been working as a software engineer since 2000, programming with C++, Java, Ruby, JavaScript, Clojure, and ClojureScript. Currently, he is a software architect at Cycognito, building software infrastructures for high-scale data pipelines. He is the author of "Data-Oriented Programming," published by Manning.
MODERATOR
Paul DeGrandis, Senior Research Director, Kevel
Paul deGrandis is the Senior Director of Research at Kevel. He is leading work in distributed systems, intelligent forecasting, and cognitive computing. Paul is a member of ACM and participates in the ACM Global Practitioner Advisory Board. He is also a member of W3C Advisory Committee and actively participates in W3C groups.
Date: January 25, 2023
Duration: 1HR
ABSTRACT
Complexity is one of the main difficulties in the development of successful software systems. Modern programming languages and frameworks make it easy to develop and deploy our code quickly, but as the code base grows, complexity makes it challenging to add new features.
Data-oriented programming is a paradigm that aims at reducing the complexity of information systems such as back-end applications, web services, web workers, and front-end applications by rethinking data. Data-oriented programming treats data as an immutable value that is manipulated by general-purpose functions. Moreover, data is validated à la carte.
In this talk, we illustrate the principles of data-oriented programming in the context of a software production system. After attending this talk, you will be able to apply data-oriented programming principles in your preferred programming language and reduce the complexity of the systems you build.
Takeaways
1. Apply Data-Oriented Programming principles in your preferred programming language.
2. Apply data validation techniques without using static types.
3. Represent data with immutable data structures.
4. Manipulate data with generic functions.
SPEAKER
Yehonathan Sharvit, Software Architect, Cycognito
Yehonathan Sharvit has been working as a software engineer since 2000, programming with C++, Java, Ruby, JavaScript, Clojure, and ClojureScript. Currently, he is a software architect at Cycognito, building software infrastructures for high-scale data pipelines. He is the author of "Data-Oriented Programming," published by Manning.
MODERATOR
Paul DeGrandis, Senior Research Director, Kevel
Paul deGrandis is the Senior Director of Research at Kevel. He is leading work in distributed systems, intelligent forecasting, and cognitive computing. Paul is a member of ACM and participates in the ACM Global Practitioner Advisory Board. He is also a member of W3C Advisory Committee and actively participates in W3C groups.
 0:08:07
0:08:07
Reduce System Complexity w/ Data-Oriented Programming in 8 Minutes • Yehonathan Sharvit • GOTO 2023...
 0:39:34
0:39:34
Reduce System Complexity with Data-Oriented Programming • Yehonathan Sharvit • GOTO 2023
 0:35:47
0:35:47
Reduce system complexity with Data-Oriented Programming by Yehonathan Sharvit
 1:00:11
1:00:11
Reduce System Complexity with Data Oriented Programming
 1:00:57
1:00:57
Reduce system complexity with Data-Oriented Programming by Yehonathan Sharvit
 1:08:24
1:08:24
Reduce system complexity with Data-Oriented programming
 0:52:26
0:52:26
Reduce system complexity with Data-Oriented programming
 0:34:46
0:34:46
Reduce system complexity in Java with Data-Oriented programming
 0:05:36
0:05:36
Octopus Energy's Fleet Card: 960,000 UK Chargers, One Payment System
 0:01:29
0:01:29
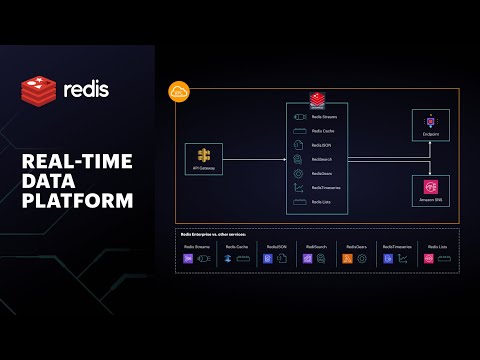
Reduce Complexity by Using Redis as a Real-Time Data Platform
 0:04:14
0:04:14
How Multi-Model Databases Reduce Data Modeling Complexity
 0:18:43
0:18:43
Reducing Complexity in Embedded Systems
 0:34:24
0:34:24
Reducing complexity and increasing performance with Trino
 0:04:33
0:04:33
Data-Oriented Programming: Reduce software complexity
 0:00:23
0:00:23
Reduce complexity with Oracle Autonomous Database
 0:02:30
0:02:30
Reduce Cost and Complexity With Hitachi’s Lumada Data Lake
 0:38:00
0:38:00
Reducing Complexity at Daimler: Look into the Data to Ask the Right Questions
 0:02:53
0:02:53
AD400x Solves Design Challenges and Reduces System Complexity
 0:15:06
0:15:06
How Can Subsampling Reduce Complexity in SMCMC Methods and Deal with Big Data in Target Tracking?
 0:00:42
0:00:42
How does complexity increase security risks? Part 3
 0:01:03
0:01:03
Save Money & Reduce Complexity of Enterprise Data Protection with NetBackup | Insight UK
 0:10:08
0:10:08
1.5.1 Time Complexity #1
 0:20:38
0:20:38
Big-O Notation - For Coding Interviews
 0:00:16
0:00:16
Cut costs and complexity with efficient monitoring
Комментарии