filmov
tv
Massive Scale Data Processing at Netflix using Flink - Snehal Nagmote & Pallavi Phadnis
Показать описание
Massive Scale Data Processing at Netflix using Flink
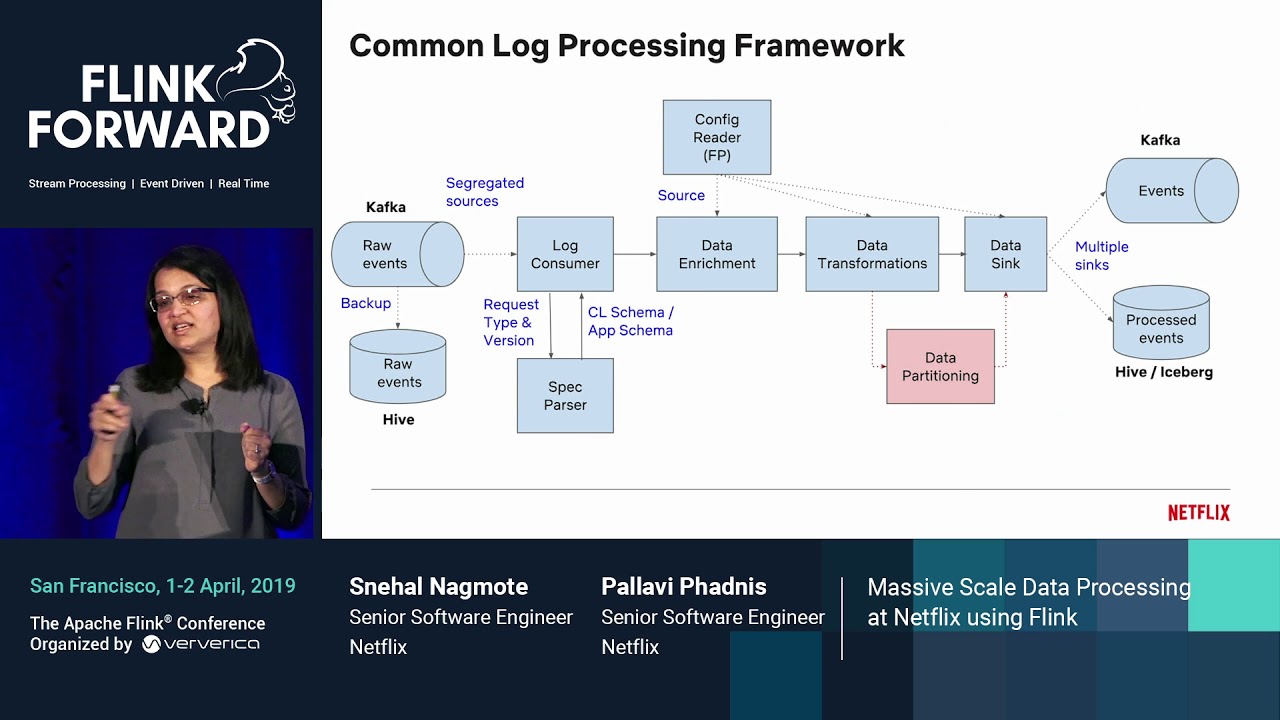
Over 137 million members worldwide are enjoying TV series, feature films across a wide variety of genres and languages on Netflix. It leads to petabyte scale of user behavior data. At Netflix, our client logging platform collects and processes this data to empower recommendations, personalization and many other services to enhance user experience. Built with Apache Flink, this platform processes 100s of billion events and a petabyte data per day, 2.5 million events/sec in sub milliseconds latency. The processing involves a series of data transformations such as decryption and data enrichment of customer, geo, device information using microservices based lookups.
The transformed and enriched data is further used by multiple data consumers for a variety of applications such as improving user-experience with A/B tests, tracking application performance metrics, tuning algorithms. This causes redundant reads of the dataset by multiple batch jobs and incurs heavy processing costs. To avoid this, we have developed a config driven, centralized, managed platform, on top of Apache Flink, that reads this data once and routes it to multiple streams based on dynamic configuration. This has resulted in improved computation efficiency, reduced costs and reduced operational overhead.
Stream processing at scale while ensuring that the production systems are scalable and cost-efficient brings interesting challenges. In this talk, we will share about how we leverage Apache Flink to achieve this, the challenges we faced and our learnings while running one of the largest Flink application at Netflix.
Flink Forward San Francisco 2019
#flinkforward
Over 137 million members worldwide are enjoying TV series, feature films across a wide variety of genres and languages on Netflix. It leads to petabyte scale of user behavior data. At Netflix, our client logging platform collects and processes this data to empower recommendations, personalization and many other services to enhance user experience. Built with Apache Flink, this platform processes 100s of billion events and a petabyte data per day, 2.5 million events/sec in sub milliseconds latency. The processing involves a series of data transformations such as decryption and data enrichment of customer, geo, device information using microservices based lookups.
The transformed and enriched data is further used by multiple data consumers for a variety of applications such as improving user-experience with A/B tests, tracking application performance metrics, tuning algorithms. This causes redundant reads of the dataset by multiple batch jobs and incurs heavy processing costs. To avoid this, we have developed a config driven, centralized, managed platform, on top of Apache Flink, that reads this data once and routes it to multiple streams based on dynamic configuration. This has resulted in improved computation efficiency, reduced costs and reduced operational overhead.
Stream processing at scale while ensuring that the production systems are scalable and cost-efficient brings interesting challenges. In this talk, we will share about how we leverage Apache Flink to achieve this, the challenges we faced and our learnings while running one of the largest Flink application at Netflix.
Flink Forward San Francisco 2019
#flinkforward
 0:49:39
0:49:39
 0:41:05
0:41:05
 0:03:36
0:03:36
 0:38:33
0:38:33
 0:46:37
0:46:37
 0:06:21
0:06:21
 0:05:12
0:05:12
 0:18:49
0:18:49
 0:01:00
0:01:00
 0:26:11
0:26:11
 0:04:46
0:04:46
 0:26:52
0:26:52
 0:04:48
0:04:48
 1:25:33
1:25:33
 0:09:36
0:09:36
 0:13:47
0:13:47
 0:05:51
0:05:51
 1:05:34
1:05:34
 0:23:30
0:23:30
 0:29:09
0:29:09
 0:22:29
0:22:29
 0:42:10
0:42:10
 0:24:29
0:24:29
 0:11:46
0:11:46